Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

1
Как устроен NoSQL Андрей Аксёнов, v.1.1, Ульяновск, Стачка 2014

2
Disclaimer Ремикс двух докладов с Highload 2013 Константин Осипов, Популярные алгоритмы хранения данных на диске Mark Callaghan, MySQL vs something else: evaluating alternative databases Ничего нового, всё скучно Только набор ключевых слов, всё крайне поверхностно (иначе нельзя) Уходите сразу

7
Зачем этот доклад? Пропаганда и разжигание Алгоритмический фундаментализм

8
Зачем этот доклад? Пропаганда и разжигание Алгоритмический фундаментализм НЕ помогу выбрать базу – бенчмаркай сам НЕ расскажу про спец грабли – невозможно НЕ буду ничего сравнивать – бессмысленно Попробую (попробую) сделать обзор фундамента, на котором Всё Стоит В объеме своего непонимания!!!
 сделать обзор фундамента, на котор")
9
Про термины Строки == документы == объекты == … Колонки == поля == значения == … Point/range lookup/read Point, WHERE id=123 Range, WHERE price>=100 AND price<=500 CSV, SQL, XML, JSON, WTF… а суть одна – документы и их части

10
Структуры данных Как хранятся собственно данные? Как хранятся индексы? Какая базовая СД хранилки Какой внутри нее (!) формат строки? Во что выливаются чтения, во что записи? Как СДХ, ФС ложатся на типичные для нашей системы запросы?
 формат строки? Во что выливаются чтения, во что записи? Как СДХ, ФС ложатся на типичные для нашей системы запросы?")
11
Про данные Структура хранения? Одинаковая ли в памяти, на диске? Отдельные строки, линейный файл Отдельные строки, B- или B+дерево Отдельные (сжатые) колонки, линейный файл Сжатые вместе блоки строк, линейный файл Сжатые наборы частей строк, блочный файл …и еще что угодно
 колонки, линейный файл Сжатые вместе блоки строк, линейный файл Сжатые наборы частей строк, блочный")
12
Про данные Формат строки (если есть)? NB, не связано со структурой хранения! Можно положить JSON в.MYD? Конечно. Можно положить BSON в.ibd? Разумеется. Ключевой выбор строчной хранилки? Схема снаружи (и некий бинарный формат) Схема внутри (и далее JSON, BSON, XML, ASN.1, MessagePack, что угодно ещё)
? NB, не связано со структурой хранения! Можно положить JSON в.MYD? Конечно. Можно положить BSON в.ibd? Разумеется. Ключевой выбор строчной хранилки? Схема снаружи (и некий бинарный формат) Схема внутри (и далее JS")
13
Про данные, NoSQL revolution! Было как-то общепринято Plain file B-tree Стало еще вдобавок LSM, Log Structured Merge Bitcask, Log Structured Hash Table Column-based LZO, LZ4, snappy, …

14
Про данные, NoSQL revolution! Было как-то общепринято Plain file1937 B-tree1972 Стало еще вдобавок LSM, Log Structured Merge1996 Bitcask, Log Structured Hash Table2010 Column-based1969!!! LZO, LZ4, snappy, … 1996

16
Про индексы, NoSQL revolution! Было как-то общепринято B-tree Стало еще вдобавок LSM + Bloom (псевдо индекс по PK) Fractal trees (LSM + forward pointer???) Column-based (псевдо индекс по колонке)
 Fractal trees (LSM + forward pointer???) Column-based (псевдо индекс по колонке)")
17
Про мишуру, NoSQL revolution! Было как-то общепринято Фиксированные схемы, реляционная модель Нормализация, JOIN SQL синтаксис Стало еще вдобавок Отсутствие схем, сплошной JSON Денормализация, шардинг REST, JSON синтаксис запросов

18
Индексы, сука, ВАЖНО Point lookup (aka read) SELECT * … WHERE id=123 Range lookup SELECT * … WHERE price>100 AND price<200 Аналитика SELECT AVG(salary) FROM emp Нету индексов – привет, полный перебор Даже для аналитики – строки vs индекс
 SELECT * … WHERE id=123 Range lookup SELECT * … WHERE price>100 AND price<200 Аналитика SELECT AVG(salary) FROM emp Нету индексов – привет, полный перебор Даже для аналитики – строки vs индекс")
19
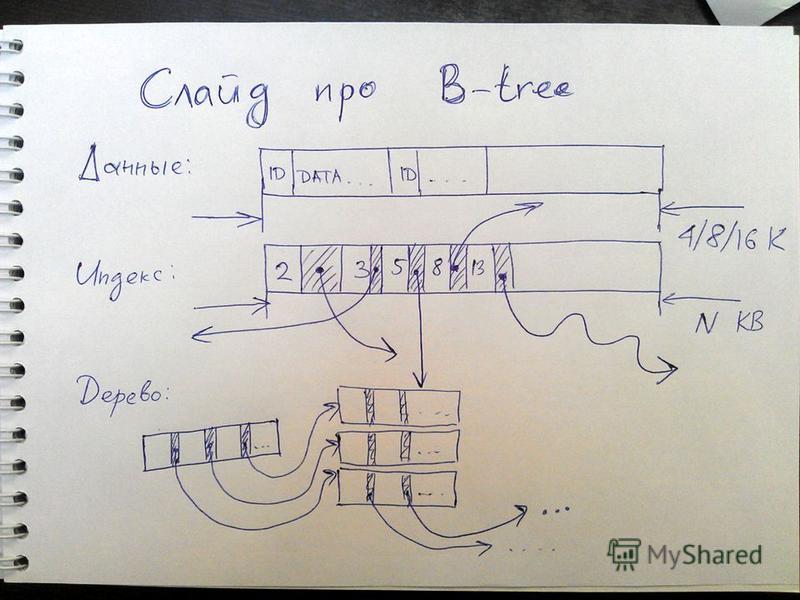
Как устроено B-tree? Дерево из больших (8..64K) страничек В узлах – тысячи пар key, offset В листах – единицы...тысячи пар key, value Разные стратегии апдейта (UIP, COW-R/S) Value – либо сама строка, либо rowptr Для данных – и то, и другое Для индексов – только rowptr
 страничек В узлах – тысячи пар key, offset В листах – единицы...тысячи пар key, value Разные стратегии апдейта (UIP, COW-R/S) Value – либо сама строка, либо rowptr Для данных – и то, и другое Для индекс")
21
Как устроены LSM/SSTable? Sorted runs, сортированные по PK строки Необязательно один файл, может, куча C0 / Memtable – sorted run в памяти C1 / L0, L1, L2, …, Lmax – sorted run на диске Разные стратегии про размер, слияния Новая строка -> mem -> L0 -> L1 -> …. Постоянное слияние, merge

24
Про тов.Bloom F{ключ} -> { сразу нет, может быть } Чем больше бит/ключ, тем точнее, ~10 ок Дико таращит для point lookups Совсем не помогает для range lookups

26
Чем отличаются Btree, LSM based? Тащемта стратегиями записи (!!!) InnoDB = Btree, UIP LMDB = Btree, COW-S LevelDB, Cassandra = LSM, leveled compact mem, L0, …, Lmax; 10x на шаг Hbase, Cassandra = LSM, n-files compact mem, L0, L1; N файлов гб в L0; 64 гб L1 Sophia, MaSM, TokuDB, …
 InnoDB = Btree, UIP LMDB = Btree, COW-S LevelDB, Cassandra = LSM, leveled compact mem, L0, …, Lmax; 10x на шаг Hbase, Cassandra = LSM, n-files compact mem, L0, L1; N файлов 1..32 гб в")
27
Как устроен Bitcask? Log-only, строки постоянно дописываются конец (текущий активный лог-файл) Кольцевой буфер логов, сборка мусора Отдельная карта ключей (PK) Все ключи – всегда в памяти В терминах RDB – это PK индексы
 Кольцевой буфер логов, сборка мусора Отдельная карта ключей (PK) Все ключи – всегда в памяти В терминах RDB – это PK индексы")
29
Как устроены column based? Строк в общем случае вообще нету Хранятся отдельные колонки, пожато SELECT * WHERE id=X довольно ужасен Потому что в пределе num_cols IO SELECT a,b,c WHERE d иногда прекрасен Когда селективность d все равно плохая Когда колонок много Когда сжатие хорошее

30
Когда Тагил рулит 1 тупое целое число в колонке RDB, NoSQL = 4 байта Columnar = байт … 4 байта RLE, 0x01 | 0xAB … PFD, 0x02 | b | 00b 00b 11b 10b … GVI, 0x01 | 0x34 0x12 | 0x56 | 0x78 | 0x9A И еще куча клёвых интересных техник

32
Итого, как хранятся строки? Классика, тупо подряд в файле Классика, B-tree Классика, не хранятся совсем (колонки) ПРОРЫВ, отсортировано в файле по PK!!! И еще немножечко сжато, может быть
 ПРОРЫВ, отсортировано в файле по PK!!! И еще немножечко сжато, может быть")
33
Итого, как хранятся индексы? Классика, B-tree Классика, не хранятся совсем (колонки) ПРОРЫВ, отсортировано в файле по PK!!! И еще немножечко Bloom filter
 ПРОРЫВ, отсортировано в файле по PK!!! И еще немножечко Bloom filter")
34
Мощный обман NoSQL Ура, больше нету ALTER, все динамично!!! Ура, можно забить на проектирование!!! Ой, это только для хранения Ой, а оно теперь жрет диск, как из пушки Ой, все равно CREATE INDEX Ой, все равно обновлять индекс стоит денег Ой, все равно проектировать-то надо

35
Так говоришь, как будто всё плохо! Ну, плохо всё, но не всё-всё-всё LSM итп таки обеспечивают Быстрые записи, append only (как MyISAM) Быстрые PK point, range (вдобавок) Важно, что неявный PK индекс тут один Важно, что хранилка != формат Важно, что другие индексы = тот же Btree… …либо поколоночное хранение
 Быстрые PK point, range (вдобавок) Важно, что неявный PK индекс тут один Важно, что хранилка != формат Важно, что д")
36
Так говоришь, как будто всё плохо! Поколоночные индексы таки обеспечивают Медленные записи, если вдруг сдуру онлайн Медленные PK point, range (Очень) эффективное хранение, (очень) быстрый перебор отдельных колонок Однако, фактически write-once, без обновлений
 эффективное хранение, (очень) быстрый перебор отдельных колонок Однако, фактически write-once, без о")
37
Эффекты усиления Read, write, space amplification Сколько байт пишем на 1 измененный 1? А что насчет WAL? А что насчет заполненности страничек? А как это работает в железе? А какой размер сектора?

38
Mark Callaghan, Highload 2013

39
А где про нови клёви JSON итп?! Синтаксис – ничто, семантика – все! SQL, XML, JSON, Put, Get, txt, wtf… … Point read, range read, full scan, etc!!! Спроси меня, как мы храним JSON в Sphinx! Спроси Бартунова, как они хранят в Pg! Спроси... или будь мужиком и читай сорс!

41
Итого Данные научились хранить в LSM, cols, жать А индексы все равно типично Btree!!! Резкий key => value это мило, но не панацея Знай, как устроено Понимай, как может исполниться запрос Планируй и выбирай соответственно Ну то есть... как обычно!!!

42
Вопросы? (Можно подумать, я уложусь в 40 мин.)
")
Еще похожие презентации в нашем архиве:













 - универсальный компьютерный.")




. База данных это информационная модель, позволяющая упорядоченно хранить данные о группе объектов, обладающих одинаковым набором.")



 Севастопольская специализированная школа I-III ступеней 3 с углублённым изучением английского языка Севастопольского городского Совета Ученица.")








