Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

1
Занятие 3 Факторы – Файлы - Статистика 23 сентября 2015 Виноградова Светлана

2
План Факторы Работа с файлами Элементарная статистика 2/42

3
Факторы 3/42

levels(f) <- c(levels(f), "maybe") " title="Факторы Используются для представления категориальных данных (да/нет, низкий/средний/высокий, мужчина/женщина…) > f f [1] yes yes no yes no Levels: no yes > levels(f) # возможные значения в факторе [1] "no" "yes" > levels(f) <- c(levels(f), "maybe") " class="link_thumb">
4
Факторы Используются для представления категориальных данных (да/нет, низкий/средний/высокий, мужчина/женщина…) > f f [1] yes yes no yes no Levels: no yes > levels(f) # возможные значения в факторе [1] "no" "yes" > levels(f) <- c(levels(f), "maybe") > table(f) f no yes maybe /42
levels(f) <- c(levels(f), "maybe") ">
levels(f) <- c(levels(f), "maybe") > table(f) f no yes maybe 2 3 0 4/42">
levels(f) <- c(levels(f), "maybe") " title="Факторы Используются для представления категориальных данных (да/нет, низкий/средний/высокий, мужчина/женщина…) > f f [1] yes yes no yes no Levels: no yes > levels(f) # возможные значения в факторе [1] "no" "yes" > levels(f) <- c(levels(f), "maybe") ">
![Факторы Используются для представления категориальных данных (да/нет, низкий/средний/высокий, мужчина/женщина…) > f f [1] yes yes no yes no Levels: no yes > levels(f) # возможные значения в факторе [1]](http://images.myshared.ru/27/1295524/slide_4.jpg)
f [1] yes yes no yes no Levels: yes no (по умолчанию, уровни в факторе упоря" title="Факторы Уровни можно упорядочивать при создании фактора (может быть важно в линейной регрессии): > f <- factor(c("yes", "yes", "no", "yes", "no"), levels = c("yes", "no")) > f [1] yes yes no yes no Levels: yes no (по умолчанию, уровни в факторе упоря" class="link_thumb">
5
Факторы Уровни можно упорядочивать при создании фактора (может быть важно в линейной регрессии): > f <- factor(c("yes", "yes", "no", "yes", "no"), levels = c("yes", "no")) > f [1] yes yes no yes no Levels: yes no (по умолчанию, уровни в факторе упорядочиваются в лексикографическом порядке) 5/42
f [1] yes yes no yes no Levels: yes no (по умолчанию, уровни в факторе упоря">
f [1] yes yes no yes no Levels: yes no (по умолчанию, уровни в факторе упорядочиваются в лексикографическом порядке) 5/42">
f [1] yes yes no yes no Levels: yes no (по умолчанию, уровни в факторе упоря" title="Факторы Уровни можно упорядочивать при создании фактора (может быть важно в линейной регрессии): > f <- factor(c("yes", "yes", "no", "yes", "no"), levels = c("yes", "no")) > f [1] yes yes no yes no Levels: yes no (по умолчанию, уровни в факторе упоря">

6
Факторы Разбиение вектора по фактору: > boxplot(mtcars$mpg ~ mtcars$cyl) mpg: … cyl: … 6/42
 mpg: 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 … cyl: 6 6 4 6 8 6 8 4 … 6/42")
7
Работа с файлами 7/42

8
Работа с файлами: основные функции Чтение ЗаписьПрименение read.tablewrite.table Чтение/запись табулированных текстовых файлов read.csvwrite.csv Чтение/запись файлов в формате CSV readLineswriteLines Чтение/запись текстовых файлов по строкам loadsave Загрузка/сохранение объектов R из/в бинарные файлы (.RData) 8/42

setwd("Week3") # путь указан относительно рабочей директории! > getwd() [1] "C:/Users/anna/FBB/R/Week3" Узнать список ф" title="Работа с файлами: рабочая директория Узнать рабочую директорию: > getwd() [1] "C:/Users/anna/FBB/R" Поменять рабочую директорию: > setwd("Week3") # путь указан относительно рабочей директории! > getwd() [1] "C:/Users/anna/FBB/R/Week3" Узнать список ф" class="link_thumb">
9
Работа с файлами: рабочая директория Узнать рабочую директорию: > getwd() [1] "C:/Users/anna/FBB/R" Поменять рабочую директорию: > setwd("Week3") # путь указан относительно рабочей директории! > getwd() [1] "C:/Users/anna/FBB/R/Week3" Узнать список файлов в рабочей директории > dir() Узнать список файлов в указанной директории > dir("C:/Users/anna/FBB/R/") В RStudio: закладка Files (справа внизу) -> выбрать нужную директорию -> More -> Set As Working Directory 9/42
setwd("Week3") # путь указан относительно рабочей директории! > getwd() [1] "C:/Users/anna/FBB/R/Week3" Узнать список ф">
setwd("Week3") # путь указан относительно рабочей директории! > getwd() [1] "C:/Users/anna/FBB/R/Week3" Узнать список файлов в рабочей директории > dir() Узнать список файлов в указанной директории > dir("C:/Users/anna/FBB/R/") В RStudio: закладка Files (справа внизу) -> выбрать нужную директорию -> More -> Set As Working Directory 9/42">
setwd("Week3") # путь указан относительно рабочей директории! > getwd() [1] "C:/Users/anna/FBB/R/Week3" Узнать список ф" title="Работа с файлами: рабочая директория Узнать рабочую директорию: > getwd() [1] "C:/Users/anna/FBB/R" Поменять рабочую директорию: > setwd("Week3") # путь указан относительно рабочей директории! > getwd() [1] "C:/Users/anna/FBB/R/Week3" Узнать список ф">
![Работа с файлами: рабочая директория Узнать рабочую директорию: > getwd() [1]](http://images.myshared.ru/27/1295524/slide_9.jpg)
students[101:102,] Name Faculty Level Year 101 Широкий В. Р. химический специалитет 4 102 Базылев С. С. б" title="Работа с файлами: read.table Читает файл с разделителями Возвращает data.frame > students <- read.table("FBBRStudents.tab",sep="\t", header=T) > students[101:102,] Name Faculty Level Year 101 Широкий В. Р. химический специалитет 4 102 Базылев С. С. б" class="link_thumb">
10
Работа с файлами: read.table Читает файл с разделителями Возвращает data.frame > students <- read.table("FBBRStudents.tab",sep="\t", header=T) > students[101:102,] Name Faculty Level Year 101 Широкий В. Р. химический специалитет Базылев С. С. биологический бакалавриат 1 10/42
students[101:102,] Name Faculty Level Year 101 Широкий В. Р. химический специалитет 4 102 Базылев С. С. б">
students[101:102,] Name Faculty Level Year 101 Широкий В. Р. химический специалитет 4 102 Базылев С. С. биологический бакалавриат 1 10/42">
students[101:102,] Name Faculty Level Year 101 Широкий В. Р. химический специалитет 4 102 Базылев С. С. б" title="Работа с файлами: read.table Читает файл с разделителями Возвращает data.frame > students <- read.table("FBBRStudents.tab",sep="\t", header=T) > students[101:102,] Name Faculty Level Year 101 Широкий В. Р. химический специалитет 4 102 Базылев С. С. б">

11
Работа с файлами: read.table Основные аргументы: file – имя файла или соединение (connection) header – есть ли в файле заголовок? (по умолчанию, FALSE) sep – разделитель полей (колонок) (по умолчанию, пробел) colClasses – вектор с названиями классов колонок nrows – количество строчек, которые нужно прочитать skip – количество строчек, которые нужно пропустить comment.char – знак комментариев stringsAsFactors – преобразовывать строковые поля в фактор? (по умолчанию, TRUE) 11/42
 header – есть ли в файле заголовок? (по умолчанию, FALSE) sep – разделитель полей (колонок) (по умолчанию, пробел) colClasses – вектор с названиями классов")
str(students) 'data.frame': 141 obs. of 4 variables: $ Name : chr "Антонов С. В." "Дмитриев Д. И." " title="Работа с файлами: read.table > students<-read.table("FBBRStudents.tab",sep="\t",header=T, + colClasses = c("character","factor","factor","integer")) > str(students) 'data.frame': 141 obs. of 4 variables: $ Name : chr "Антонов С. В." "Дмитриев Д. И." " class="link_thumb">
12
Работа с файлами: read.table > students<-read.table("FBBRStudents.tab",sep="\t",header=T, + colClasses = c("character","factor","factor","integer")) > str(students) 'data.frame': 141 obs. of 4 variables: $ Name : chr "Антонов С. В." "Дмитриев Д. И." "Золотов И. А." "Иванова Т. В."... $ Faculty: Factor w/ 10 levels "биологический",..: $ Level : Factor w/ 3 levels "бакалавриат",..: $ Year : int /42
str(students) 'data.frame': 141 obs. of 4 variables: $ Name : chr "Антонов С. В." "Дмитриев Д. И." ">
str(students) 'data.frame': 141 obs. of 4 variables: $ Name : chr "Антонов С. В." "Дмитриев Д. И." "Золотов И. А." "Иванова Т. В."... $ Faculty: Factor w/ 10 levels "биологический",..: 3 3 3 3 3 3 3 3 3 3... $ Level : Factor w/ 3 levels "бакалавриат",..: 3 3 3 3 3 3 3 3 3 3... $ Year : int 3 3 3 3 4 4 4 4 4 4... 12/42">
str(students) 'data.frame': 141 obs. of 4 variables: $ Name : chr "Антонов С. В." "Дмитриев Д. И." " title="Работа с файлами: read.table > students<-read.table("FBBRStudents.tab",sep="\t",header=T, + colClasses = c("character","factor","factor","integer")) > str(students) 'data.frame': 141 obs. of 4 variables: $ Name : chr "Антонов С. В." "Дмитриев Д. И." ">

lines <- readLines("FBBRStudents" title="Работа с файлами: read.csv, write.csv, readLines read.csv – то же, что read.table, но c другими дефолтными значениями параметров ( header=TRUE, sep=, ) write.csv: > write.csv(students, "FBBRStudents.csv") readLines: > lines <- readLines("FBBRStudents" class="link_thumb">
13
Работа с файлами: read.csv, write.csv, readLines read.csv – то же, что read.table, но c другими дефолтными значениями параметров ( header=TRUE, sep=, ) write.csv: > write.csv(students, "FBBRStudents.csv") readLines: > lines <- readLines("FBBRStudents.txt,3) > lines [1] "Name\tFaculty\tLevel\tYear" [2] "Антонов С. В.\tмеханико- математический\tспециалитет\t3" [3] "Дмитриев Д. И.\tмеханико- математический\tспециалитет\t3" 13/42
lines <- readLines("FBBRStudents">
lines <- readLines("FBBRStudents.txt,3) > lines [1] "Name\tFaculty\tLevel\tYear" [2] "Антонов С. В.\tмеханико- математический\tспециалитет\t3" [3] "Дмитриев Д. И.\tмеханико- математический\tспециалитет\t3" 13/42">
lines <- readLines("FBBRStudents" title="Работа с файлами: read.csv, write.csv, readLines read.csv – то же, что read.table, но c другими дефолтными значениями параметров ( header=TRUE, sep=, ) write.csv: > write.csv(students, "FBBRStudents.csv") readLines: > lines <- readLines("FBBRStudents">

rm(list=ls()) > ls() character(0) Загружаем объекты из файла: > load("Students.RDat" title="Работа с файлами: save, load Сохраняем объекты students и lines в файл: > save(students, lines, file="Students.RData") Удаляем все объекты из рабочего пространства: > rm(list=ls()) > ls() character(0) Загружаем объекты из файла: > load("Students.RDat" class="link_thumb">
14
Работа с файлами: save, load Сохраняем объекты students и lines в файл: > save(students, lines, file="Students.RData") Удаляем все объекты из рабочего пространства: > rm(list=ls()) > ls() character(0) Загружаем объекты из файла: > load("Students.RData") > ls() [1] "lines" "students # объекты появляются в # рабочем пространстве 14/42
rm(list=ls()) > ls() character(0) Загружаем объекты из файла: > load("Students.RDat">
rm(list=ls()) > ls() character(0) Загружаем объекты из файла: > load("Students.RData") > ls() [1] "lines" "students # объекты появляются в # рабочем пространстве 14/42">
rm(list=ls()) > ls() character(0) Загружаем объекты из файла: > load("Students.RDat" title="Работа с файлами: save, load Сохраняем объекты students и lines в файл: > save(students, lines, file="Students.RData") Удаляем все объекты из рабочего пространства: > rm(list=ls()) > ls() character(0) Загружаем объекты из файла: > load("Students.RDat">

readLines(con, 1) [1] "Name\tFaculty\tLevel\tYear" > rea" title="Соединения file – открывает соединение с файлом gzfile, bzfile – открывает соединение с архивированным файлом url – открывает соединение с веб-страницей > con <- file("FBBRStudents.txt", "r") > readLines(con, 1) [1] "Name\tFaculty\tLevel\tYear" > rea" class="link_thumb">
15
Соединения file – открывает соединение с файлом gzfile, bzfile – открывает соединение с архивированным файлом url – открывает соединение с веб-страницей > con <- file("FBBRStudents.txt", "r") > readLines(con, 1) [1] "Name\tFaculty\tLevel\tYear" > readLines(con, 1) [1] "Антонов С. В.\tмеханико-математический\tспециалитет\t3" > close(con) > con <- gzfile("FBBRStudents.gz") > read.csv(con, nrow=2) X Name Faculty Level Year 1 1 Антонов С. В. механико-математический специалитет Дмитриев Д. И. механико-математический специалитет 3 > close(con) 15/42
readLines(con, 1) [1] "Name\tFaculty\tLevel\tYear" > rea">
readLines(con, 1) [1] "Name\tFaculty\tLevel\tYear" > readLines(con, 1) [1] "Антонов С. В.\tмеханико-математический\tспециалитет\t3" > close(con) > con <- gzfile("FBBRStudents.gz") > read.csv(con, nrow=2) X Name Faculty Level Year 1 1 Антонов С. В. механико-математический специалитет 3 2 2 Дмитриев Д. И. механико-математический специалитет 3 > close(con) 15/42">
readLines(con, 1) [1] "Name\tFaculty\tLevel\tYear" > rea" title="Соединения file – открывает соединение с файлом gzfile, bzfile – открывает соединение с архивированным файлом url – открывает соединение с веб-страницей > con <- file("FBBRStudents.txt", "r") > readLines(con, 1) [1] "Name\tFaculty\tLevel\tYear" > rea">

16
Элементарная статистика 16/42

17
Эксперимент: как отличить «честную» монетку от «нечестной»? Честная монетка: вероятность орла 0.5, вероятность решки 0.5 Нечестная монетка: вероятность орла 0.2, вероятность решки 0.8 Подбросим монетку 100 раз. Решка выпала 70 раз. Какая у нас монетка? Насколько можно быть уверенным в этом? 17/42

18
Распределение частот выпадения решки у честной монеты (биномиальное распределение): N=70 H0 – нулевая гипотеза: мы кидали честную монету H1 – альтернативная гипотеза: монета кривая 18/42
: N=70 H0 – нулевая гипотеза: мы кидали честную монету H1 – альтернативная гипотеза: монета кривая 18/42")
19
наблюдаемое значение статистики P-value (уровень значимости) Что такое P-value? Вероятность наблюдаемого при нулевой гипотезе Вероятность ошибочно отвергнуть нулевую гипотезу (когда она верна) Не строгие математические определения, главное – понять смысл! 19/42
 Что такое P-value? Вероятность наблюдаемого при нулевой гипотезе Вероятность ошибочно отвергнуть нулевую гипотезу (когда она верна) Не строгие математические определения, главное – понять с")
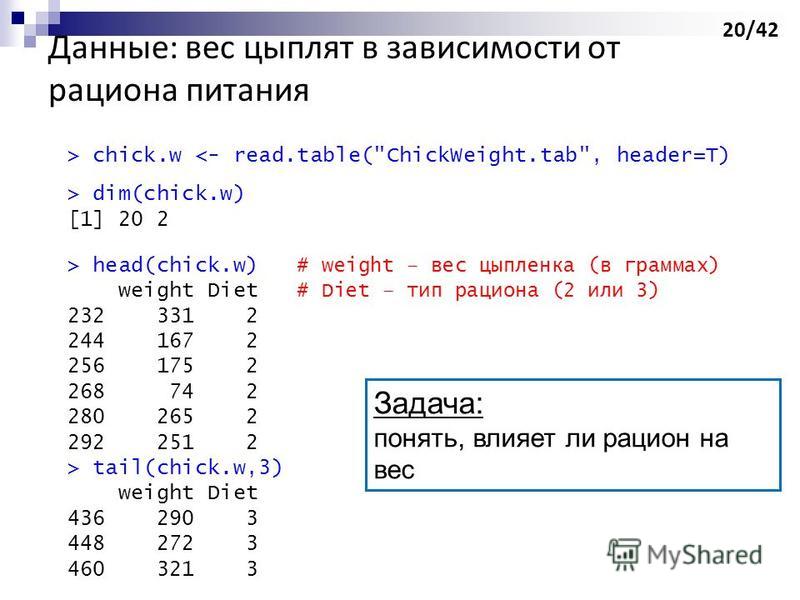
dim(chick.w) [1] 20 2 > head(chick.w) # weight – вес цыпленка (в граммах) weight Diet # Diet – тип рациона (2 или 3) 232 331 2 244 167 2 256 17" title="Данные: вес цыплят в зависимости от рациона питания > chick.w <- read.table("ChickWeight.tab", header=T) > dim(chick.w) [1] 20 2 > head(chick.w) # weight – вес цыпленка (в граммах) weight Diet # Diet – тип рациона (2 или 3) 232 331 2 244 167 2 256 17" class="link_thumb">
20
Данные: вес цыплят в зависимости от рациона питания > chick.w <- read.table("ChickWeight.tab", header=T) > dim(chick.w) [1] 20 2 > head(chick.w) # weight – вес цыпленка (в граммах) weight Diet # Diet – тип рациона (2 или 3) > tail(chick.w,3) weight Diet Задача: понять, влияет ли рацион на вес 20/42
dim(chick.w) [1] 20 2 > head(chick.w) # weight – вес цыпленка (в граммах) weight Diet # Diet – тип рациона (2 или 3) 232 331 2 244 167 2 256 17">
dim(chick.w) [1] 20 2 > head(chick.w) # weight – вес цыпленка (в граммах) weight Diet # Diet – тип рациона (2 или 3) 232 331 2 244 167 2 256 175 2 268 74 2 280 265 2 292 251 2 > tail(chick.w,3) weight Diet 436 290 3 448 272 3 460 321 3 Задача: понять, влияет ли рацион на вес 20/42">
dim(chick.w) [1] 20 2 > head(chick.w) # weight – вес цыпленка (в граммах) weight Diet # Diet – тип рациона (2 или 3) 232 331 2 244 167 2 256 17" title="Данные: вес цыплят в зависимости от рациона питания > chick.w <- read.table("ChickWeight.tab", header=T) > dim(chick.w) [1] 20 2 > head(chick.w) # weight – вес цыпленка (в граммах) weight Diet # Diet – тип рациона (2 или 3) 232 331 2 244 167 2 256 17">
21
Вопрос 1 Как распределена каждая выборка? Сравнение распределения выборки с заданным теоретическим распределением 21/42

22
1. Графический анализ выборок Являются ли выборки нормальными? Из одного ли они распределения? Вес цыплят в зависимости от рациона питания 22/42

23
Сравнение формы распределений графически qqplot – рисует квантили одной выборки напротив другой qqnorm – рисует квантили выборки против квантилей нормального распределения qqline – рисует линию, проходящую через 1 и 3 квартили теоретического (нормального) распределения 23/42

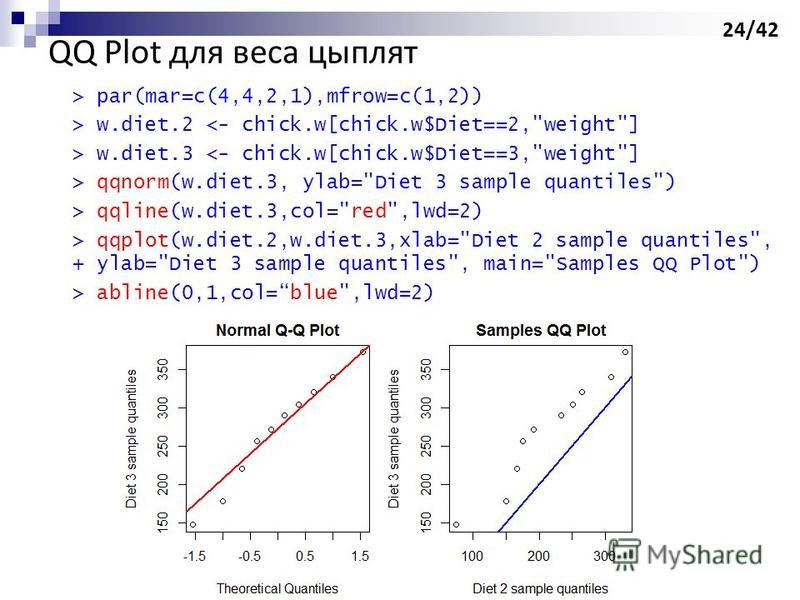
w.diet.3 <- chick.w[chick.w$Diet==3,"weight"] > qqnorm(w.diet.3, ylab="Diet 3 sample quantiles") > qqline(w.diet.3,col="red",lwd=2) > qqplot(" title="QQ Plot для веса цыплят > par(mar=c(4,4,2,1),mfrow=c(1,2)) > w.diet.2 <- chick.w[chick.w$Diet==2,"weight"] > w.diet.3 <- chick.w[chick.w$Diet==3,"weight"] > qqnorm(w.diet.3, ylab="Diet 3 sample quantiles") > qqline(w.diet.3,col="red",lwd=2) > qqplot(" class="link_thumb">
24
QQ Plot для веса цыплят > par(mar=c(4,4,2,1),mfrow=c(1,2)) > w.diet.2 <- chick.w[chick.w$Diet==2,"weight"] > w.diet.3 <- chick.w[chick.w$Diet==3,"weight"] > qqnorm(w.diet.3, ylab="Diet 3 sample quantiles") > qqline(w.diet.3,col="red",lwd=2) > qqplot(w.diet.2,w.diet.3,xlab="Diet 2 sample quantiles", + ylab="Diet 3 sample quantiles", main="Samples QQ Plot") > abline(0,1,col=blue",lwd=2) 24/42
w.diet.3 <- chick.w[chick.w$Diet==3,"weight"] > qqnorm(w.diet.3, ylab="Diet 3 sample quantiles") > qqline(w.diet.3,col="red",lwd=2) > qqplot(">
w.diet.3 <- chick.w[chick.w$Diet==3,"weight"] > qqnorm(w.diet.3, ylab="Diet 3 sample quantiles") > qqline(w.diet.3,col="red",lwd=2) > qqplot(w.diet.2,w.diet.3,xlab="Diet 2 sample quantiles", + ylab="Diet 3 sample quantiles", main="Samples QQ Plot") > abline(0,1,col=blue",lwd=2) 24/42">
w.diet.3 <- chick.w[chick.w$Diet==3,"weight"] > qqnorm(w.diet.3, ylab="Diet 3 sample quantiles") > qqline(w.diet.3,col="red",lwd=2) > qqplot(" title="QQ Plot для веса цыплят > par(mar=c(4,4,2,1),mfrow=c(1,2)) > w.diet.2 <- chick.w[chick.w$Diet==2,"weight"] > w.diet.3 <- chick.w[chick.w$Diet==3,"weight"] > qqnorm(w.diet.3, ylab="Diet 3 sample quantiles") > qqline(w.diet.3,col="red",lwd=2) > qqplot(">
25
Статистические тесты для сравнения распределений Тест Колмогорова-Смирнова: чувствителен к отличиям в форме распределений и их сдвигу относительно друг друга H 0 : распределения совпадают плохо работает на маленьких выборках применим только для непрерывных распределений наблюдаемое значение статистики P-value (уровень значимости) Распределение статистики при нулевой гипотезе Сравнение эмпирического и теоретического распределений 25/42

26
Сравнение эмпирического распределения с теоретическим: # тест на нормальность > ks.test(w.diet.3,"pnorm",mean(w.diet.3),sd(w.diet.3)) One-sample Kolmogorov-Smirnov test data: w.diet.3 D = , p-value = alternative hypothesis: two-sided Сравнение распределений двух выборок: > ks.test(w.diet.2,w.diet.3) Two-sample Kolmogorov-Smirnov test data: w.diet.2 and w.diet.3 D = 0.4, p-value = alternative hypothesis: two-sided Статистические тесты для сравнения распределений 26/42
ks.test(w.diet.2,w.diet.3) Two-sample Kolmogorov-Smirnov test data: w.diet.2 and w.diet.3 D = 0.4, p-value = 0.4175 alternative hypothesis: two-sided Статистические тесты для сравнения распределений 26/42">

names(die" title="Многие статистические тесты в R возвращают объект класса htest: > diet3. ks diet3. ks Two-sample Kolmogorov-Smirnov test data: w.diet.2 and w.diet.3 D = 0.4, p-value = 0.4175 alternative hypothesis: two-sided > class(diet3.ks) [1] "htest" > names(die" class="link_thumb">
27
Многие статистические тесты в R возвращают объект класса htest: > diet3. ks diet3. ks Two-sample Kolmogorov-Smirnov test data: w.diet.2 and w.diet.3 D = 0.4, p-value = alternative hypothesis: two-sided > class(diet3.ks) [1] "htest" > names(diet3.ks) [1] "statistic" "p.value" "alternative" "method" [5] "data.name" > diet3.ks$statistic D 0.4 > diet3.ks$p.value [1] Объект класса htest 27/42
names(die">
names(diet3.ks) [1] "statistic" "p.value" "alternative" "method" [5] "data.name" > diet3.ks$statistic D 0.4 > diet3.ks$p.value [1] 0.4175 Объект класса htest 27/42">
names(die" title="Многие статистические тесты в R возвращают объект класса htest: > diet3. ks diet3. ks Two-sample Kolmogorov-Smirnov test data: w.diet.2 and w.diet.3 D = 0.4, p-value = 0.4175 alternative hypothesis: two-sided > class(diet3.ks) [1] "htest" > names(die">
![Многие статистические тесты в R возвращают объект класса htest: > diet3. ks diet3. ks Two-sample Kolmogorov-Smirnov test data: w.diet.2 and w.diet.3 D = 0.4, p-value = 0.4175 alternative hypothesis: two-sided > class(diet3.ks) [1]](http://images.myshared.ru/27/1295524/slide_27.jpg)
28
Тест Shapiro-Wilk: проверяет гипотезу, что выборка пришла из нормального распределения H 0 : выборка является нормальной мощнее, чем тест Колмогорова-Смирнова (то есть с меньшей вероятностью ошибочно принимает H 0 ) размер выборки от 3 до 5000 > shapiro.test(w.diet.3) # возвращает объект htest Shapiro-Wilk normality test data: w.diet.3 W = , p-value = > shapiro.test(w.diet.2)$p.value [1] Статистические тесты для сравнения распределений 28/42
 размер выборки от 3 до 5000 > shap")
29
Сдвинуты ли выборки друг относительно друга? Вопрос 2 Выборки (почти) нормальные Выборки совсем не нормальные Выборки независимые t-тест – проверяет равенство средних U-критерий Манна-Уитни (Критерий суммы рангов Уилкоксона) Kolmogorov-Smirnov test Парные выборки Парный t-test – проверяет равенство разности случайных величин нулю Т-Критерий Вилкоксона 29/42
 нормальные Выборки совсем не нормальные Выборки независимые t-тест – проверяет равенство средних U-критерий Манна-Уитни (Критерий суммы рангов Уилкоксона) Kolmogorov-Smirnov test П")
30
Students (Gossets) t-тест Введен Вильямом Госсетом в 1908 для оценки качества пива на пивоварне Guinness Используется для: проверки равенства выборочного среднего заданному значению проверки равенства средних значений двух серий измерений, сделанных для тех же объектов в разных условиях (например, состояние пациентов до и после лечения) – paired t-test проверки равенства средних двух независимых выборок Предполагается, что случайные величины распределены примерно нормально При больших размерах выборок, распределение t- статистики приближается к нормальному Распределение t-статистики two.sided greaterless 30/42
 t-тест Введен Вильямом Госсетом в 1908 для оценки качества пива на пивоварне Guinness Используется для: проверки равенства выборочного среднего заданному значению проверки равенства средних значений двух серий измерений, сделанных")
chick.test <-t.test(chick.w$weight ~ chick.w$Diet, alternative="less") > chick.test$p.value Welch Two Sample t-test data: chick.w$weight by chick.w$Diet t = -1.6588," title="Способ 1: > chick.test <- t.test(w.diet.2, w.diet.3, alternative="less") Способ 2: > chick.test <-t.test(chick.w$weight ~ chick.w$Diet, alternative="less") > chick.test$p.value Welch Two Sample t-test data: chick.w$weight by chick.w$Diet t = -1.6588," class="link_thumb">
31
Способ 1: > chick.test <- t.test(w.diet.2, w.diet.3, alternative="less") Способ 2: > chick.test <-t.test(chick.w$weight ~ chick.w$Diet, alternative="less") > chick.test$p.value Welch Two Sample t-test data: chick.w$weight by chick.w$Diet t = , df = , p-value = alternative hypothesis: true difference in means is less than 0 95 percent confidence interval: -Inf sample estimates: mean in group 2 mean in group t-test для независимых выборок 31/42
chick.test <-t.test(chick.w$weight ~ chick.w$Diet, alternative="less") > chick.test$p.value Welch Two Sample t-test data: chick.w$weight by chick.w$Diet t = -1.6588,">
chick.test <-t.test(chick.w$weight ~ chick.w$Diet, alternative="less") > chick.test$p.value Welch Two Sample t-test data: chick.w$weight by chick.w$Diet t = -1.6588, df = 17.865, p-value = 0.05731 alternative hypothesis: true difference in means is less than 0 95 percent confidence interval: -Inf 2.548154 sample estimates: mean in group 2 mean in group 3 214.7 270.3 t-test для независимых выборок 31/42">
chick.test <-t.test(chick.w$weight ~ chick.w$Diet, alternative="less") > chick.test$p.value Welch Two Sample t-test data: chick.w$weight by chick.w$Diet t = -1.6588," title="Способ 1: > chick.test <- t.test(w.diet.2, w.diet.3, alternative="less") Способ 2: > chick.test <-t.test(chick.w$weight ~ chick.w$Diet, alternative="less") > chick.test$p.value Welch Two Sample t-test data: chick.w$weight by chick.w$Diet t = -1.6588,">

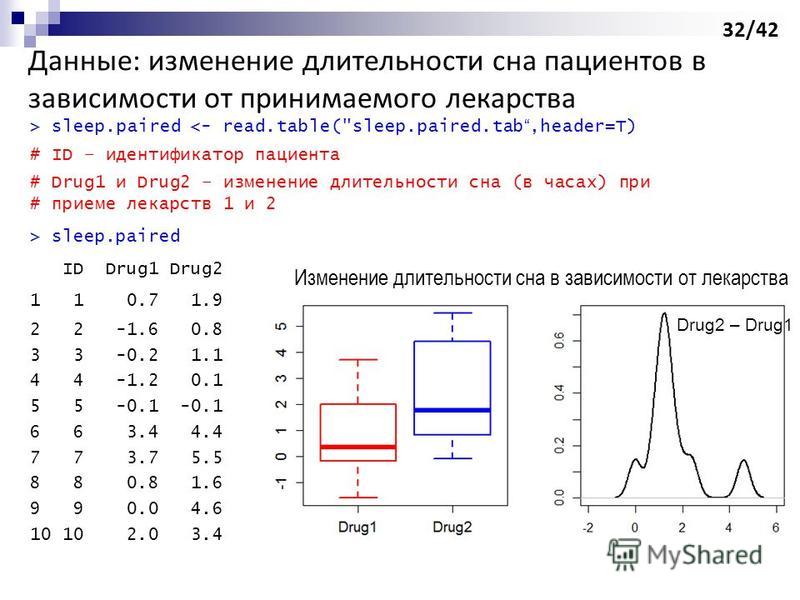
sleep.paired ID Drug1 Drug2 1 1 0.7 1.9 2 2 -1.6 0.8 3 3 -0.2 1.1 4 4 -1.2 0.1" title="> sleep.paired <- read.table("sleep.paired.tab,header=T) # ID – идентификатор пациента # Drug1 и Drug2 – изменение длительности сна (в часах) при # приеме лекарств 1 и 2 > sleep.paired ID Drug1 Drug2 1 1 0.7 1.9 2 2 -1.6 0.8 3 3 -0.2 1.1 4 4 -1.2 0.1" class="link_thumb">
32
> sleep.paired <- read.table("sleep.paired.tab,header=T) # ID – идентификатор пациента # Drug1 и Drug2 – изменение длительности сна (в часах) при # приеме лекарств 1 и 2 > sleep.paired ID Drug1 Drug Данные: изменение длительности сна пациентов в зависимости от принимаемого лекарства Изменение длительности сна в зависимости от лекарства Drug2 – Drug1 32/42
sleep.paired ID Drug1 Drug2 1 1 0.7 1.9 2 2 -1.6 0.8 3 3 -0.2 1.1 4 4 -1.2 0.1">
sleep.paired ID Drug1 Drug2 1 1 0.7 1.9 2 2 -1.6 0.8 3 3 -0.2 1.1 4 4 -1.2 0.1 5 5 -0.1 -0.1 6 6 3.4 4.4 7 7 3.7 5.5 8 8 0.8 1.6 9 9 0.0 4.6 10 10 2.0 3.4 Данные: изменение длительности сна пациентов в зависимости от принимаемого лекарства Изменение длительности сна в зависимости от лекарства Drug2 – Drug1 32/42">
sleep.paired ID Drug1 Drug2 1 1 0.7 1.9 2 2 -1.6 0.8 3 3 -0.2 1.1 4 4 -1.2 0.1" title="> sleep.paired <- read.table("sleep.paired.tab,header=T) # ID – идентификатор пациента # Drug1 и Drug2 – изменение длительности сна (в часах) при # приеме лекарств 1 и 2 > sleep.paired ID Drug1 Drug2 1 1 0.7 1.9 2 2 -1.6 0.8 3 3 -0.2 1.1 4 4 -1.2 0.1">
33
Сдвинуты ли выборки друг относительно друга? Вопрос 2 Выборки (почти) нормальные Выборки совсем не нормальные Выборки независимые t-тест – проверяет равенство средних U-критерий Манна-Уитни (Критерий суммы рангов Уилкоксона) Kolmogorov-Smirnov test Парные выборки Парный t-test – проверяет равенство разности случайных величин нулю Т-Критерий Вилкоксона 33/42
 нормальные Выборки совсем не нормальные Выборки независимые t-тест – проверяет равенство средних U-критерий Манна-Уитни (Критерий суммы рангов Уилкоксона) Kolmogorov-Smirnov test П")
diff <- sleep.paired$after - sleep.paired$before > t.test(diff) # объект htest " title="Помогло ли лекарство - стали ли пациенты дольше спать? Способ 1: > sleep.test <- t.test(sleep.paired$Drug1, + sleep.paired$Drug2, paired=T, alternative=less") Способ 2: > diff <- sleep.paired$after - sleep.paired$before > t.test(diff) # объект htest " class="link_thumb">
34
Помогло ли лекарство - стали ли пациенты дольше спать? Способ 1: > sleep.test <- t.test(sleep.paired$Drug1, + sleep.paired$Drug2, paired=T, alternative=less") Способ 2: > diff <- sleep.paired$after - sleep.paired$before > t.test(diff) # объект htest One Sample t-test data: diff t = , df = 9, p-value = alternative hypothesis: true mean is greater than 0 95 percent confidence interval: Inf sample estimates: mean of x 1.58 Если забыть указать, что тест парный: > t.test(sleep.paired$Drug1, sleep.paired$Drug2, alternative="less")$p.value [1] Парный t-тест 34/42
diff <- sleep.paired$after - sleep.paired$before > t.test(diff) # объект htest ">
diff <- sleep.paired$after - sleep.paired$before > t.test(diff) # объект htest One Sample t-test data: diff t = 4.0621, df = 9, p-value = 0.001416 alternative hypothesis: true mean is greater than 0 95 percent confidence interval: 0.8669947 Inf sample estimates: mean of x 1.58 Если забыть указать, что тест парный: > t.test(sleep.paired$Drug1, sleep.paired$Drug2, alternative="less")$p.value [1] 0.03969707 Парный t-тест 34/42">
diff <- sleep.paired$after - sleep.paired$before > t.test(diff) # объект htest " title="Помогло ли лекарство - стали ли пациенты дольше спать? Способ 1: > sleep.test <- t.test(sleep.paired$Drug1, + sleep.paired$Drug2, paired=T, alternative=less") Способ 2: > diff <- sleep.paired$after - sleep.paired$before > t.test(diff) # объект htest ">

head(rt) Mean.RT Group 1 13" title="Данные: влияние анестетика на время реакции пациентов на световой раздражитель rt <- read.table("anaesthetic.reaction.time.tab", sep="\t", header=T) # Mean.RT – среднее время реакции; Group: A/B – with/without anesthetic > head(rt) Mean.RT Group 1 13" class="link_thumb">
35
Данные: влияние анестетика на время реакции пациентов на световой раздражитель rt <- read.table("anaesthetic.reaction.time.tab", sep="\t", header=T) # Mean.RT – среднее время реакции; Group: A/B – with/without anesthetic > head(rt) Mean.RT Group B A B B A B Больше ли время реакции у пациентов под воздействием анестетика? reaction time (sec) 35/42
head(rt) Mean.RT Group 1 13">
head(rt) Mean.RT Group 1 131 B 2 135 A 3 138 B 4 138 B 5 139 A 6 141 B Больше ли время реакции у пациентов под воздействием анестетика? reaction time (sec) 35/42">
head(rt) Mean.RT Group 1 13" title="Данные: влияние анестетика на время реакции пациентов на световой раздражитель rt <- read.table("anaesthetic.reaction.time.tab", sep="\t", header=T) # Mean.RT – среднее время реакции; Group: A/B – with/without anesthetic > head(rt) Mean.RT Group 1 13">

36
Сдвинуты ли выборки друг относительно друга? Вопрос 2 Выборки (почти) нормальные Выборки совсем не нормальные Выборки независимые t-тест – проверяет равенство средних U-критерий Манна-Уитни (Критерий суммы рангов Уилкоксона) Kolmogorov-Smirnov test Парные выборки Парный t-test – проверяет равенство разности случайных величин нулю Т-Критерий Вилкоксона 36/42
 нормальные Выборки совсем не нормальные Выборки независимые t-тест – проверяет равенство средних U-критерий Манна-Уитни (Критерий суммы рангов Уилкоксона) Kolmogorov-Smirnov test П")
37
U-критерий Манна-Уитни Используется для тестирования гипотезы, что значения в одной из выборок в среднем (стохастически) больше, чем в другой H 0 : выборки не отличаются Позволяет выявлять различия в значении параметра между малыми выборками При больших размерах выборок, распределение U- cстатистики приближается к нормальному 37/42
 больше, чем в другой H 0 : выборки не отличаются Позволяет выявлять различия в значении параметра между малыми выборками При боль")
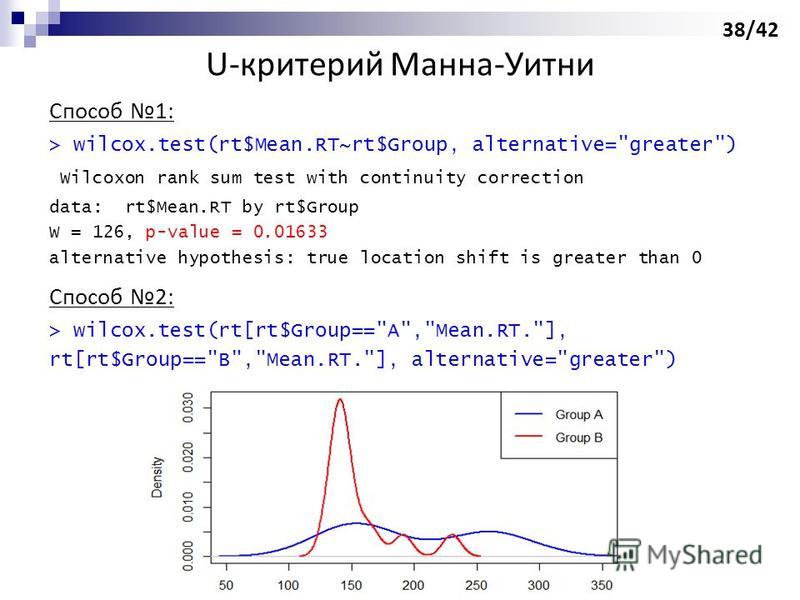
wi" title="Способ 1: > wilcox.test(rt$Mean.RT~rt$Group, alternative="greater") Wilcoxon rank sum test with continuity correction data: rt$Mean.RT by rt$Group W = 126, p-value = 0.01633 alternative hypothesis: true location shift is greater than 0 Способ 2: > wi" class="link_thumb">
38
Способ 1: > wilcox.test(rt$Mean.RT~rt$Group, alternative="greater") Wilcoxon rank sum test with continuity correction data: rt$Mean.RT by rt$Group W = 126, p-value = alternative hypothesis: true location shift is greater than 0 Способ 2: > wilcox.test(rt[rt$Group=="A","Mean.RT."], rt[rt$Group=="B","Mean.RT."], alternative="greater") U-критерий Манна-Уитни 38/42
wi">
wilcox.test(rt[rt$Group=="A","Mean.RT."], rt[rt$Group=="B","Mean.RT."], alternative="greater") U-критерий Манна-Уитни 38/42">
wi" title="Способ 1: > wilcox.test(rt$Mean.RT~rt$Group, alternative="greater") Wilcoxon rank sum test with continuity correction data: rt$Mean.RT by rt$Group W = 126, p-value = 0.01633 alternative hypothesis: true location shift is greater than 0 Способ 2: > wi">
head(test) Student Q1 Q2 1 1 78 67 2 2 24 24 3 3 64 62 4 4 55 58 5 5 74 28 6 6 52 36 Данные: ответы студентов на вопросы" title="> test <- read.csv("StudentTest.csv") # Student – студент, отвечающий на вопрос # Q1, Q2 – баллы (от 0 до 100) за 1 и 2 вопросы > head(test) Student Q1 Q2 1 1 78 67 2 2 24 24 3 3 64 62 4 4 55 58 5 5 74 28 6 6 52 36 Данные: ответы студентов на вопросы" class="link_thumb">
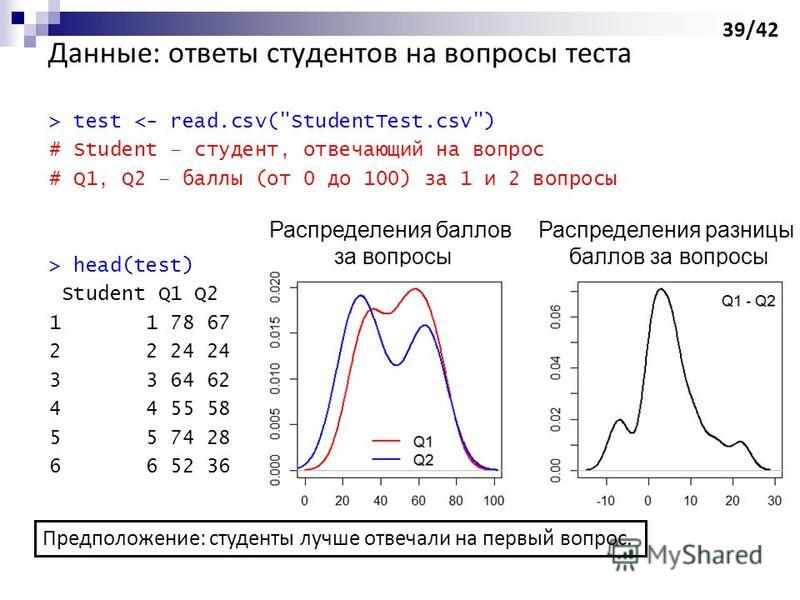
39
> test <- read.csv("StudentTest.csv") # Student – студент, отвечающий на вопрос # Q1, Q2 – баллы (от 0 до 100) за 1 и 2 вопросы > head(test) Student Q1 Q Данные: ответы студентов на вопросы теста Предположение: студенты лучше отвечали на первый вопрос. Распределения баллов за вопросы Распределения разницы баллов за вопросы 39/42
head(test) Student Q1 Q2 1 1 78 67 2 2 24 24 3 3 64 62 4 4 55 58 5 5 74 28 6 6 52 36 Данные: ответы студентов на вопросы">
head(test) Student Q1 Q2 1 1 78 67 2 2 24 24 3 3 64 62 4 4 55 58 5 5 74 28 6 6 52 36 Данные: ответы студентов на вопросы теста Предположение: студенты лучше отвечали на первый вопрос. Распределения баллов за вопросы Распределения разницы баллов за вопросы 39/42">
head(test) Student Q1 Q2 1 1 78 67 2 2 24 24 3 3 64 62 4 4 55 58 5 5 74 28 6 6 52 36 Данные: ответы студентов на вопросы" title="> test <- read.csv("StudentTest.csv") # Student – студент, отвечающий на вопрос # Q1, Q2 – баллы (от 0 до 100) за 1 и 2 вопросы > head(test) Student Q1 Q2 1 1 78 67 2 2 24 24 3 3 64 62 4 4 55 58 5 5 74 28 6 6 52 36 Данные: ответы студентов на вопросы">
40
Сдвинуты ли выборки друг относительно друга? Вопрос 2 Выборки (почти) нормальные Выборки совсем не нормальные Выборки независимые t-тест – проверяет равенство средних U-критерий Манна-Уитни (Критерий суммы рангов Уилкоксона) Kolmogorov-Smirnov test Парные выборки Парный t-test – проверяет равенство разности случайных величин нулю Т-Критерий Вилкоксона 40/42
 нормальные Выборки совсем не нормальные Выборки независимые t-тест – проверяет равенство средних U-критерий Манна-Уитни (Критерий суммы рангов Уилкоксона) Kolmogorov-Smirnov test П")
41
Т-Критерий Вилкоксона Способ 1: > wilcox.test(test$Q1, test$Q2, paired=T, alternative="greater", exact=F) Wilcoxon signed rank test with continuity correction data: test$Q1 and test$Q2 V = 114.5, p-value = alternative hypothesis: true location shift is greater than 0 Способ 2: > wilcox.test(test$Q1-test$Q2, alternative="greater", exact=F) Предположение, что студены лучше отвечали на первый вопрос, подтвердилось на 1% уровне значимости. 41/42
wilcox.test(test$Q1-test$Q2, alternative="greater", exact=F) Предположение, что студены лучше отвечали на первый вопрос, подтвердилось на 1% уровне значимости. 41/42">

42
Элементарная статистика: типичные вопросы Как распределены наблюдения в выборке? является ли выборка нормальной? (ks.test, shapiro.test) Сравнение двух выборок: из одного ли они распределения? (ks.test) сдвину-ты ли они друг относительно друга? (t.test, wilcox.test, ks.test) 42/42
 Сравнение двух выборок: из одного ли они распределения? (ks.test) сдвину-ты ли они друг относительно друга? (t.te")
Еще похожие презентации в нашем архиве:











 - отсутствующие данные Исходные данные могут быть введены: путем набора область.")








