Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

2
Содержание ВремяТема – Часть 1. Введение в параллелизм (коротко). Знакомство с WHPC. Знакомство с примером. Запуск первой программы на кластере. Распараллеливание задачи. Многопоточное программирование – Часть 2. Первая программа на MPI. Распараллеливание задачи на MPI – Часть 3. Отладка параллельных программ. Оптимизация параллельных приложений. Параллелизм в управляемом коде, MPI.NET.
. Знакомство с WHPC. Знакомство с примером. Запуск первой программы на кластере. Распараллеливание задачи. Многопоточное программирование. 21.07.09 15-00 – 16-00 Час")
3
Инфраструктура Туалеты Перерывы Эвакуация != Тренеры Денис Котляров, Microsoft Василий Маланин, Microsoft Андрей Паринов, Независимый эксперт Группа поддержки

6
Часть 1. Введение в параллелизм. Многопоточное программирование.

7
Введение -Зачем? -Типы параллелизма. -Ускорение -> Эффективность vs Переносимость -Распараллеливание = Инструменты && (Предметные области || Задачи)
")
8
Описание предметной области

10
Описание предметной области

11
n = количество проц. T паралл. = { (1-P) + P/n } T послед Ускорение = T послед / T паралл. Закон Амдала Описывает верхний предел ускорения от параллельного выполнения Последовательный код ограничивает ускорение (1-P) P T Послед. (1-P) P/2 P/
 + P/n } T послед Ускорение = T послед / T паралл. Закон Амдала Описывает верхний предел ускорения от параллельного выполнения Последовательный код ограничивает ускорение (1-P) P T Послед. (1-P) P/2 P/")
12
Проведение вычислений на локальной машине Для проведения эксперимента необходимо открыть в в VS 2008 проект из папки Solutions\Sequential\SeqContrastStretch\ Необходимо выбрать архитектуру процессора, на которому будут провиодиться вычисления. Для проведение вычислений на кластере необходимо выбрать 64-х битную архитектуру процессора.

13
Проведение вычислений на локальной машине

14
Постановка задач для кластера в HPCS Адрес MSU кластера \ IKI кластераHN.PRACTICUM.CS.MSU.SU \ Имя головного узла (head node) hn.practicum\hn.cluster.local Имя вычислительных узлов cn1,cn2…\ cn1.cluster.local,cn2.cluster.local… Сетевая папка доступная всем hn.practicum\apps \ hn.cluster.local\apps вычислительным узлам Сетевая папка на каждом \\cn1\Apps, \\cn2\Apps... \ cn1.cluster.local\apps вычилительном узле (физический расположенная в C:\Apps) Для доступа к IKI кластеру необходимо включить VPN соединение, указав User name: Password: Domain: Cluster
 hn.practicum\hn.cluster.local Имя вычислительных узлов cn1,cn2…\ cn1.cluster.local,cn2.cluster.local… Сетевая")
15
WHPCS

16
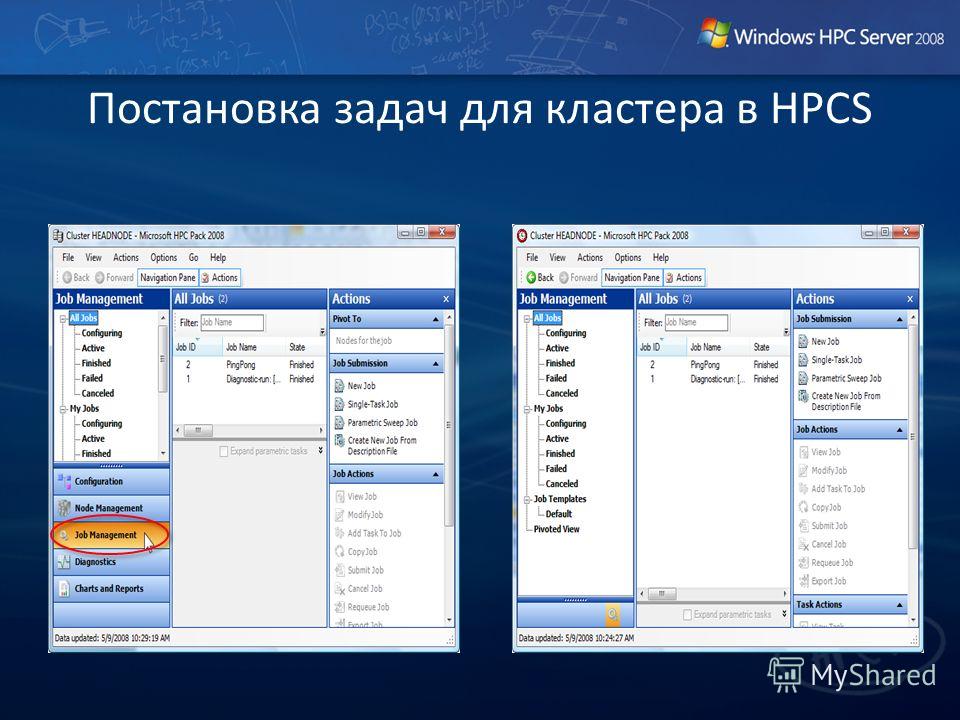
Постановка задач для кластера в HPCS

19
Для последовательных и OpenMP программ: app.exe argument1 argument2... Для программы MPI: mpiexec mpiapp.exe argument1 argument2...

20
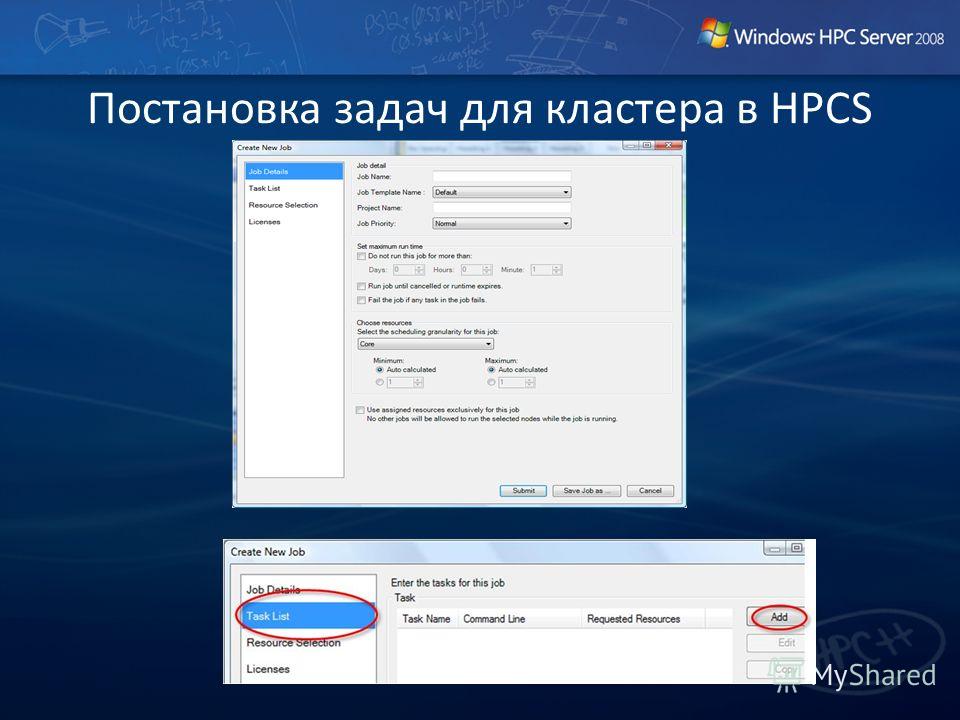
Постановка задач для кластера в HPCS 6) После сохранения задачи, нажмите кнопку «Submit». Должно появится окно подтверждения прав для постановки задачи. Необходимо ввести имя пользователя и пароль. Например, если имя пользователя domain\hpcuser, то окно будет иметь вид
 После сохранения задачи, нажмите кнопку «Submit». Должно появится окно подтверждения прав для постановки задачи. Необходимо ввести имя пользователя и пароль. Например, если имя пользователя domain\hpcuser, то о")
21
Постановка задач для кластера в HPCS

22
Для просмотра загруженности вычислительных узлов при выполнении задачи, необходимо открыть вкладку Heat Map в Windows HPC Server. Например, вид окна должен быть таким:

23
Постановка задач для кластера в HPCS Консоли : > job submit /scheduler:headnode /jobname:MyJob /numprocessors:1-1 /exclusive:true /workdir:\\headnode\Public\DrJoe /stdout:_OUT.txt /stderr:_ERR.txt /user:domain\hpcuser SeqContrastStretch.exe Sunset.bmp result.bmp 75 1 Windows PowerShell : > $job = new-hpcjob –scheduler "headnode" –name "MyJob" – numprocessors "1-1" –exclusive 1 > add-hpctask –scheduler "headnode" –job $job –workdir "\\headnode\Public\DrJoe" –stdout "_OUT.txt" –stderr "_ERR.txt" – command "SeqContrastStretch.exe Sunset.bmp result.bmp 75 1" > submit-hpcjob –scheduler "headnode" –job $job –credential "domain\hpcuser"
add-hpctask –scheduler "headnode" –job $job –workdir "\\headnode\Public\DrJoe" –stdout "_OUT.txt" –stderr "_ERR.txt" – command "SeqContrastStretch.exe Sunset.bmp result.bmp 75 1" > submit-hpcjob –scheduler "headnode" –job $job –credential "domain\hpcuser"">

24
Последовательно о многопоточном.

25
Процессы и потоки Преимущества потоков: Быстрое переключение между потоками (переключение между процессами очень ресурсоемкая операция) Простая организация взаимодействия – общая память Недостатки потоков: Некорректное использование данных одним потоком отражается на всех других Необходимость в синхронизации при доступе к общим данным Используемые библиотеки должны поддерживать многопоточность Сегмент кода Сегмент данных thread main() … thread Stack
 Простая организация взаимодействия – общая память Недостатки потоков: Некорректное использование данных одним пото")
26
Средства создания многопоточных программ Ручные: Библиотеки потоков – Posix Threads – Windows Threads – … Полуавтоматические: OpenMP Автоматические: Распараллеливающие компиляторы Неявный параллелизм (F#)
")
27
Синхронизация потоков Необходима при: Совместном использовании ресурса (атомарные операции) Уведомлении потоков о некотором событии
 Уведомлении потоков о некотором событии")
28
n = количество проц. T паралл. = { (1-P) + P/n } T послед Ускорение = T послед / T паралл. Закон Амдала Описывает верхний предел ускорения от параллельного выполнения Последовательный код ограничивает ускорение (1-P) P T Послед. (1-P) P/2 P/
 + P/n } T послед Ускорение = T послед / T паралл. Закон Амдала Описывает верхний предел ускорения от параллельного выполнения Последовательный код ограничивает ускорение (1-P) P T Послед. (1-P) P/2 P/")
29
29 Parallel Programming Models Functional Decomposition – Task parallelism – Divide the computation, then associate the data – Independent tasks of the same problem Data Decomposition – Same operation performed on different data – Divide data into pieces, then associate computation

30
Просто OpenMP Параллелизм Fork-join: Главный поток (Master thread) порождает группу потоков по необходимости Параллелизм добавляется постепенно –Последовательная программа трансформируется в параллельную Параллельные регионы Главный поток
 порождает группу потоков по необходимости Параллелизм добавляется постепенно –Последовательная программа трансформируется в параллельную Параллельные регионы Главный поток")
31
Параллельные циклы Определите циклы на вычисление которых уходит наибольшее количество времени. Распределите их о выполнение между потоками. #include omp.h void main() { double Res[1000]; #pragma omp parallel for for(int i=0;i
![Параллельные циклы Определите циклы на вычисление которых уходит наибольшее количество времени. Распределите их о выполнение между потоками. #include omp.h void main() { double Res[1000]; #pragma omp parallel for for(int i=0;i](http://images.myshared.ru/5/498400/slide_31.jpg "Параллельные циклы Определите циклы на вычисление которых уходит наибольшее количество времени. Распределите их о выполнение между потоками. #include omp.h void main() { double Res[1000]; #pragma omp parallel for for(int i=0;i")
32
Примитивы OpenMP подразделяются на категории: – Функции времени выполнения/переменные среды окружения – Параллельные регионы – Распределение работ – Синхронизация Принципиально OpenMP не зависит от компилятора или языка, например Fortran и C/C++ Просто OpenMP

33
Примитивы среды окружения: Изменить/проверить количество потоков – omp_set_num_threads() – omp_get_num_threads() – omp_get_thread_num() – omp_get_max_threads() Мы в параллельном регионе? – omp_in_parallel() Сколько процессоров в системе? – omp_num_procs() Функции
 – omp_get_num_threads() – omp_get_thread_num() – omp_get_max_threads() Мы в параллельном регионе? – omp_in_parallel() Сколько процессоров в системе? – omp_num_pr")
34
Чтобы установить количество потоков #include void main() { int num_threads; omp_set_num_threads(omp_num_procs()); #pragma omp parallel { int id=omp_get_thread_num(); #pragma omp single num_threads = omp_get_num_threads(); do_lots_of_stuff(id); } } Функции Установить количество потоков равное количеству процессоров Глоб. Переменная. Операция выполняется в одном потоке.
 { int num_threads; omp_set_num_threads(omp_num_procs()); #pragma omp parallel { int id=omp_get_thread_num(); #pragma omp single num_threads = omp_get_num_threads(); do_lots_of_stuff(id); } } Фу")
35
Установить количество потоков, порождаемых по умолчанию – OMP_NUM_THREADS int_literal Установить способ распределения нагрузки по умолчанию – OMP_SCHEDULE schedule[, chunk_size] Переменные среды коружения
![Установить количество потоков, порождаемых по умолчанию – OMP_NUM_THREADS int_literal Установить способ распределения нагрузки по умолчанию – OMP_SCHEDULE schedule[, chunk_size] Переменные среды коружения](http://images.myshared.ru/5/498400/slide_35.jpg "Установить количество потоков, порождаемых по умолчанию – OMP_NUM_THREADS int_literal Установить способ распределения нагрузки по умолчанию – OMP_SCHEDULE schedule[, chunk_size] Переменные среды коружения")
36
Правила разделения переменных Неявное правило 1: Все переменные, определенные вне omp parallel, являются глобальными для всех потоков Неявное правило 2: Все переменные, определенные внутри omp parallel, являются локальными для каждого потока Неявное исключение: В прагме omp for, счетчик цикла всегда локален для каждого потока Явное правило 1: Переменные, приведенные в shared(), являются глобальными для всех потоков Явное правило 2: Переменные, приведенные в private(), являются локальными для каждого потока

37
Какие переменные локальные, а какие глобальные? void func() { int a, i; #pragma omp parallel for \ shared(c) private(d, e) for (i = 0; i < N; i++) { int b, c, d, e; a = a + b; c = c + d * e; }
 { int a, i; #pragma omp parallel for \ shared(c) private(d, e) for (i = 0; i < N; i++) { int b, c, d, e; a = a + b; c = c + d * e; }")
38
Прагмы синхронизации #pragma omp single – исполняет следующую команду только с помощью одного (случайного) потока #pragma omp barrier – удерживает потоки в этом месте, пока все потоки не дойдут дотуда #pragma omp atomic – атомарно исполняет следующую операцию доступа к памяти (т.е. без прерывания от других ветвей) #pragma omp critical [ имя потока ] – позволяет только одному потоку перейти к исполнению следующей команды int a[N], sum = 0; #pragma omp parallel for for (int i = 0; i < N; i++) { #pragma omp critical sum += a[i]; // one thread at a time }
 потока #pragma omp barrier – удерживает потоки в этом месте, пока все потоки не дойдут дотуда #pragma omp atomic – атомарно исполняет следующую")
39
Реализация параллельного алгоритма с использованием OpenMP Применяется OpenMP с помощью указания директив. Например : #pragma omp parallel for for (int i = 0; i < N; i++) PerformSomeComputation(i);
 PerformSomeComputation(i);")
40
Выполнение упражнения 1. В папке Exercises\02 OpenMP\OpenMPContrastStretch\ находится копия последовательной программы. Выберите необходимую архитектуру процессора ( Win32 или 64) и включите поддержку OpenMP. Измените файл app.h добавив строку #Include. Измените главную фунцию добавив строки, выводящие информацию о среде выполнения: cout
 и включите поддержку OpenMP. Измените файл app.h добавив строку #Inclu")
41
Реализация параллельного алгоритма с использованием OpenMP Поддержка OpenMP включается в Visual Studio 2005 и Visual Studio Project ->Properties->Configuration Properties-> C/C++-> Language-> OpenMP Support

42
Ошибка(!) Гонки данных. Взаимоблокировки.
 Гонки данных. Взаимоблокировки.")
43
Реализация параллельного алгоритма с использованием OpenMP Важно помнить про ситуацию (race conditions), которая возникает при одновременном доступе к общим переменным. #pragma omp parallel for schedule(static) for (int i = 0; i < N; i++) PerformSomeComputation(i); Пусть функция PerformSomeComputation изменяет значение глобальной переменной int global = 0; void PerformSomeComputation(int i) { global += i; }.
, которая возникает при одновременном доступе к общим переменным. #pragma omp parallel for schedule(static) for (int i = 0; i < N; i++) PerformSome")
44
Реализация параллельного алгоритма с использованием OpenMP Избежать ситуацию возникновения гонки за ресурсами. Позволяет использование критических секций: void PerformSomeComputation(int i) { #pragma omp critical { global += i; }
 { #pragma omp critical { global += i; }")
45
Выполнение упражнения #pragma omp parallel for schedule(static) reduction(+:diffs) for (int row = 1; row < rows-1; row++)
 reduction(+:diffs) for (int row = 1; row < rows-1; row++)")
Еще похожие презентации в нашем архиве:










")
 Киреев С.Е., Маркова В.П., Остапкевич М.Б., Перепелкин В.А. МО ВВС ИВМиМГ СО РАН.")














