Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

1
Mining Association Rules Part II

2
Data Mining Overview Data Mining Data warehouses and OLAP (On Line Analytical Processing.) Association Rules Mining Clustering: Hierarchical and Partitional approaches Classification: Decision Trees and Bayesian classifiers Sequential Patterns Mining Advanced topics: outlier detection, web mining
 Association Rules Mining Clustering: Hierarchical and Partitional approaches Classification: Decision Trees and Bayesian classifiers Sequential Patterns Mining")
3
Problem Statement I = { i 1, i 2, …, i m }: a set of literals, called items Transaction T : a set of items s.t. T I Database D : a set of transactions A transaction contains X, a set of items in I, if X T An association rule is an implication of the form X Y, where X,Y I The rule X Y holds in the transaction set D with confidence c if c% of transactions in D that contain X also contain Y The rule X Y has support s in the transaction set D if s% of transactions in D contain X Y Find all rules that have support and confidence greater than user- specified min support and min confidence

4
Problem Decomposition 1. Find all sets of items that have minimum support (frequent itemsets) 2. Use the frequent itemsets to generate the desired rules
 2. Use the frequent itemsets to generate the desired rules")
5
Mining Frequent Itemsets: the Key Step Find the frequent itemsets: the sets of items that have minimum support A subset of a frequent itemset must also be a frequent itemset i.e., if {AB} is a frequent itemset, both {A} and {B} should be a frequent itemset Iteratively find frequent itemsets with cardinality from 1 to k (k-itemset) Use the frequent itemsets to generate association rules.

6
The Apriori Algorithm L k : Set of frequent itemsets of size k (those with min support) C k : Set of candidate itemset of size k (potentially frequent itemsets) L 1 = {frequent items}; for (k = 1; L k != ; k++) do begin C k+1 = candidates generated from L k ; for each transaction t in database do increment the count of all candidates in C k+1 that are contained in t L k+1 = candidates in C k+1 with min_support end return k L k ;
 C k : Set of candidate itemset of size k (potentially frequent itemsets) L 1 = {frequent items}; for (k = 1; L k != ; k++) do begin C k+1 = candidates generated f")
7
How to Generate Candidates? Suppose the items in L k-1 are listed in order Step 1: self-joining L k-1 insert into C k select p.item 1, p.item 2, …, p.item k-1, q.item k-1 from L k-1 p, L k-1 q where p.item 1 =q.item 1, …, p.item k-2 =q.item k-2, p.item k-1 < q.item k- 1 Step 2: pruning forall itemsets c in C k do forall (k-1)-subsets s of c do if (s is not in L k-1 ) then delete c from C k

8
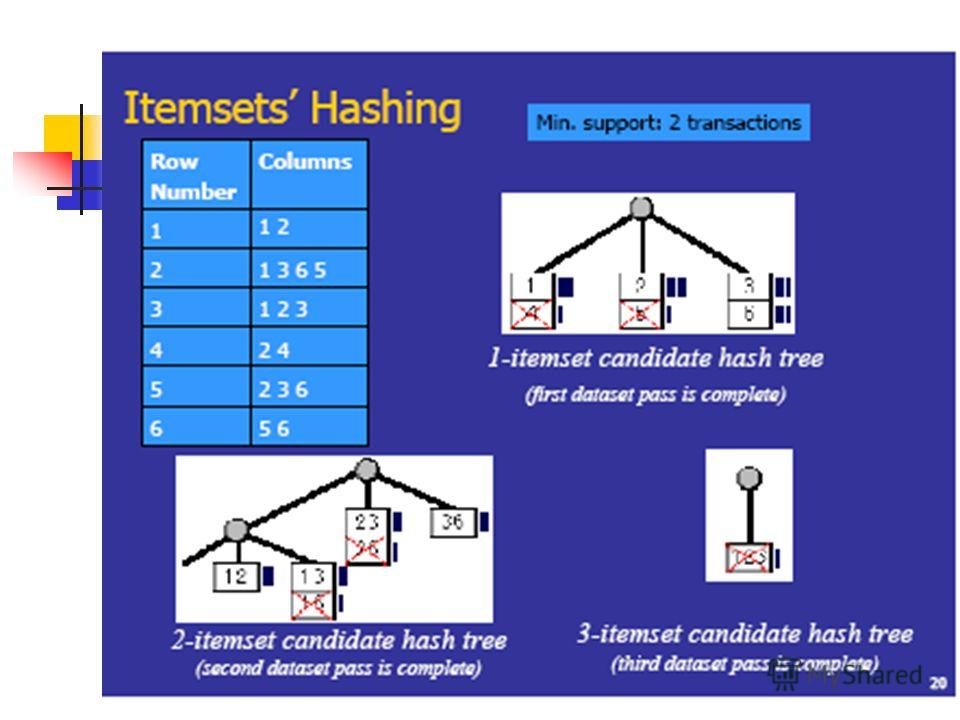
How to Count Supports of Candidates? Why counting supports of candidates a problem? The total number of candidates can be very huge One transaction may contain many candidates Method: Candidate itemsets are stored in a hash-tree Leaf node of hash-tree contains a list of itemsets and counts Interior node contains a hash table Subset function: finds all the candidates contained in a transaction

9
Hash-tree:search Given a transaction T and a set C k find all of its members contained in T Assume an ordering on the items Start from the root, use every item in T to go to the next node If you are at an interior node and you just used item i, then use each item that comes after i in T If you are at a leaf node check the itemsets

10
Is Apriori Fast Enough? Performance Bottlenecks The core of the Apriori algorithm: Use frequent (k – 1)-itemsets to generate candidate frequent k-itemsets Use database scan and pattern matching to collect counts for the candidate itemsets The bottleneck of Apriori: candidate generation Huge candidate sets: 10 4 frequent 1-itemset will generate 10 7 candidate 2-itemsets To discover a frequent pattern of size 100, e.g., {a 1, a 2, …, a 100 }, one needs to generate candidates. Multiple scans of database: Needs (n +1 ) scans, n is the length of the longest pattern
-itemsets to generate candidate frequent k-itemsets Use database scan and pattern matching to collect counts for the candidate itemsets The bottlen")
11
Max-Miner Max-miner finds long patterns efficiently: the maximal frequent patterns Instead of checking all subsets of a long pattern try to detect long patterns early Scales linearly to the size of the patterns

12
Max-Miner: the idea ,21,31,42,32,4 3,4 1,2,3 1,2,41,3,4 1,2,3,4 2,3,4 Set enumeration tree of an ordered set Pruning: (1) set infrequency (2) Superset frequency Each node is a candidate group g h(g) is the head: the itemset of the node t(g) tail: an ordered set that contains all items that can appear in the subnodes Example: h({1}) = {1} and t({1}) = {2,3,4}
 set infrequency (2) Superset frequency Each node is a candidate group g h(g) is the head: the itemset of the node t(g)")
13
Max-miner pruning When we count the support of a candidate group g, we compute also the support for h(g), h(g) t(g) and h(g) {i} for each i in t(g) If h(g) t(g) is frequent, then stop expanding the node g and report the union as frequent itemset If h(g) {i} is infrequent, then remove i from all subnodes (just remove i from any tail of a group after g) Expand the node g by one and do the same
, h(g) t(g) and h(g) {i} for each i in t(g) If h(g) t(g) is frequent, then stop expanding the node g and report the union as frequent itemset If h")
14
The algorithm Max-Miner Set candidate groups C {} Set of Itemsets F {Gen-Initial-Groups(T,C)} while C not empty do scan T to count the support of all candidate groups in C for each g in C s.t. h(g) U t(g) is frequent do F F U {h(g) U t(g)} Set candidate groups C new { } for each g in C such that h(g) U t(g) is infrequent do F F U {Gen-sub-nodes(g, C new )} C C new remove from F any itemset with a proper superset in F remove from C any group g s.t. h(g) U t(g) has a superset in F return F
} while C not empty do scan T to count the support of all candidate groups in C for each g in C s.t. h(g) U t(g) is frequent do F F U {h(g) U t(g)} Set candid")
15
The algorithm (2) Gen-Initial-Groups(T, C) scan T to obtain F 1, the set of frequent 1-itemsets impose an ordering on items in F 1 for each item i in F 1 other than the greatest itemset do let g be a new candidate with h(g) = {i} and t(g) = {j | j follows i in the ordering} C C U {g} return the itemset F 1 (an the C of course) Gen-sub-nodes(g, C) /* generation of new itemsets at the next level*/ remove any item i from t(g) if h(g) U {i} is infrequent reorder the items in t(g) for each i in t(g) other than the greatest do let g be a new candidate with h(g) = h(g) U {i} and t(g) = {j | j in t(g) and j is after i in t(g)} C C U {g} return h(g) U {m} where m is the greatest item in t(g) or h(g) if t(g) is empty
 Gen-Initial-Groups(T, C) scan T to obtain F 1, the set of frequent 1-itemsets impose an ordering on items in F 1 for each item i in F 1 other than the greatest itemset do let g be a new candidate with h(g) = {i} and t(g) = {j | j fo")
16
Item Ordering By re-ordering items we try to increase the effectiveness of frequency-pruning Very frequent items have higher probability to be contained in long patterns Put these item at the end of the ordering, so they appear in many tails

17
Mining Frequent Patterns Without Candidate Generation Compress a large database into a compact, Frequent-Pattern tree (FP-tree) structure highly condensed, but complete for frequent pattern mining avoid costly database scans Develop an efficient, FP-tree-based frequent pattern mining method A divide-and-conquer methodology: decompose mining tasks into smaller ones Avoid candidate generation: sub-database test only!
 structure highly condensed, but complete for frequent pattern mining avoid costly database scans Develop an efficient, FP-")
18
Обобщенные правила Определение 5. Правило X Y является ближайшим предком правила X Y, если не существует такого правила X' Y', что X' Y' – это предок X Y и X Y – это предок X' Y'. Подобные определения можно дать и для правил: X Y, X Y.

19
Рассмотрим правило X Y. Пусть Z = X Y. Заметим что supp(X Y) = supp(Z). Назовем E Z (Pr(Z)) ожидаемым значением Pr(Z) относительно Z. Пусть Z={z 1, …, z n }, Z={z 1, …, z j, z j+1, …, z n }, 1
 = supp(Z). Назовем E Z (Pr(Z)) ожидаемым значением Pr(Z) относительно Z. Пусть Z={z 1, …, z n }, Z={z 1, …, z j, z j+1, …, z n }, 1")
20
ожидаемое значение достоверности правила X Y относительно X Y. Пусть Y={y 1, …, y n }, Y={y 1, …, y j, y j+1 …, y n }, 1

21
Определение 6. Правило X Y называется R- интересным относительно правила-предка, если поддержка правила X Y в R раз больше ожидаемой поддержки правила X Y относительно правила-предка или если достоверность правила X Y в R раз больше ожидаемой достоверности правила X Y относительно правила-предка.

22
Определение 7. Правило называется интересным, если у него нет предков или оно является R интересным относительно всех своих ближайших предков. Определение 8. Правило называется частично интересным, если у него нет предков или оно является R-интересным относительно любого своего ближайшего предка.

23
Пример. Пусть в результате работы алгоритмы мы получили следующие правила (табл. 1.1). Поддержка элементов входящих в них приведена в табл Иерархия элементов дана рис.1. Уровень интереса R=1.3. N правилаТекст правила Поддержка, % 1 Сок Молочные продукты 10 2 Безалкогольные напитки Кефир 15 3 Сок Кефир 9
. Поддержка элементов входящих в них приведена в табл. 1.2. Иерархия элементов дана рис.1. Уровень интереса R=1.3. N правилаТекст правила Поддержка, % 1 Сок Молочные")
24
Таблица Поддержка элементов Элемент Поддержка, % Напитки7 Безалкогольные напитки 5 Сок3 Молочные продукты6 Кефир4

25
Проверим гипотезы Правило 2 является ближним предком правила 3, посчитаем ожидаемую поддержку. Неравенство Не выполняется

26
выполняется

27
Лемма 1. Поддержка множества X, содержащего и элемент x и его предок x вычисляется по формуле supp(X)=supp(X-x). Лемма 2. Если Lk – это список часто встречающихся множеств, не содержащий множеств, включающих и элемент и его предок в одном множестве, то Ck+1 (список кандидатов, получаемых из Lk) также не будет содержать множеств, включающих и элемент и его предок.
=supp(X-x). Лемма 2. Если Lk – это список часто встречающихся множеств, не содержащий множеств, включающих и элемент и его предок в одном множестве,")
28
// Оптимизация 1 Вычислить I* множества предков элементов для каждого элемента; L 1 = {Часто встречающиеся множества элементов и групп элементов}; для ( k = 2; L k-1 ; k++ ) { C k = {Генерация кандидатов мощностью k на основе L k-1 }; // Оптимизация 2 если k = 2 то удалить те кандидаты из C k, которые содержат элемент и его предок; // Оптимизация 3 Пометить как удаленные множества предков элемента, который не содержится в списке кандидатов; для всех транзакций t D { // Оптимизация 3 для каждого элемента х t добавить всех предков х из I* к t; Удалить дубликаты из транзакции t; // Оптимизация 4,5 если (t не помечена как удаленная) и ( |t| >= k) то { для всех кандидатов с C k если с t то c.count++; // Оптимизация 5 если в транзакцию t не вошел ни один кандидат то пометить эту транзакцию как удаленную; } // Отбор кандидатов L k = { с >= C k | c.count >= minsupp }; } Результат = U k L k ;
 { C k = {Генерация кандидатов мощностью k на основе L k-1 }; // Оптимизация")
30
Construct FP-tree from a Transaction DB {} f:4c:1 b:1 p:1 b:1c:3 a:3 b:1m:2 p:2m:1 Header Table Item frequency head f4 c4 a3 b3 m3 p3 min_support = 0.5 TIDItems bought (ordered) frequent items 100{f, a, c, d, g, i, m, p}{f, c, a, m, p} 200{a, b, c, f, l, m, o}{f, c, a, b, m} 300 {b, f, h, j, o}{f, b} 400 {b, c, k, s, p}{c, b, p} 500 {a, f, c, e, l, p, m, n}{f, c, a, m, p} Steps: 1.Scan DB once, find frequent 1-itemset (single item pattern) 2.Order frequent items in frequency descending order 3.Scan DB again, construct FP-tree
 frequent items 100{f, a, c, d, g, i, m, p}{f, c, a, m, p} 200{a, b, c, f")
31
Benefits of the FP-tree Structure Completeness: never breaks a long pattern of any transaction preserves complete information for frequent pattern mining Compactness reduce irrelevant informationinfrequent items are gone frequency descending ordering: more frequent items are more likely to be shared never be larger than the original database (if not count node-links and counts) Example: For Connect-4 DB, compression ratio could be over 100

32
Mining Frequent Patterns Using FP-tree General idea (divide-and-conquer) Recursively grow frequent pattern path using the FP- tree Method For each item, construct its conditional pattern-base, and then its conditional FP-tree Repeat the process on each newly created conditional FP-tree Until the resulting FP-tree is empty, or it contains only one path (single path will generate all the combinations of its sub-paths, each of which is a frequent pattern)
 Recursively grow frequent pattern path using the FP- tree Method For each item, construct its conditional pattern-base, and then its conditional FP-tree Repeat the process on ea")
33
Major Steps to Mine FP-tree 1)Construct conditional pattern base for each node in the FP-tree 2)Construct conditional FP-tree from each conditional pattern-base 3)Recursively mine conditional FP-trees and grow frequent patterns obtained so far If the conditional FP-tree contains a single path, simply enumerate all the patterns
Construct conditional pattern base for each node in the FP-tree 2)Construct conditional FP-tree from each conditional pattern-base 3)Recursively mine conditional FP-trees and grow frequent patterns obtained so far If the")
34
Step 1: From FP-tree to Conditional Pattern Base Starting at the frequent header table in the FP-tree Traverse the FP-tree by following the link of each frequent item Accumulate all of transformed prefix paths of that item to form a conditional pattern base Conditional pattern bases itemcond. pattern base cf:3 afc:3 bfca:1, f:1, c:1 mfca:2, fcab:1 pfcam:2, cb:1 {} f:4c:1 b:1 p:1 b:1c:3 a:3 b:1m:2 p:2m:1 Header Table Item frequency head f4 c4 a3 b3 m3 p3

35
Properties of FP-tree for Conditional Pattern Base Construction Node-link property For any frequent item a i, all the possible frequent patterns that contain a i can be obtained by following a i 's node-links, starting from a i 's head in the FP-tree header Prefix path property To calculate the frequent patterns for a node a i in a path P, only the prefix sub-path of a i in P need to be accumulated, and its frequency count should carry the same count as node a i.

36
Step 2: Construct Conditional FP-tree For each pattern-base Accumulate the count for each item in the base Construct the FP-tree for the frequent items of the pattern base m-conditional pattern base: fca:2, fcab:1 {} f:3 c:3 a:3 m-conditional FP-tree All frequent patterns concerning m m, fm, cm, am, fcm, fam, cam, fcam {} f:4c:1 b:1 p:1 b:1c:3 a:3 b:1m:2 p:2m:1 Header Table Item frequency head f4 c4 a3 b3 m3 p3

37
Mining Frequent Patterns by Creating Conditional Pattern-Bases Empty f {(f:3)}|c{(f:3)}c {(f:3, c:3)}|a{(fc:3)}a Empty{(fca:1), (f:1), (c:1)}b {(f:3, c:3, a:3)}|m{(fca:2), (fcab:1)}m {(c:3)}|p{(fcam:2), (cb:1)}p Conditional FP-treeConditional pattern-base Item
}|c{(f:3)}c {(f:3, c:3)}|a{(fc:3)}a Empty{(fca:1), (f:1), (c:1)}b {(f:3, c:3, a:3)}|m{(fca:2), (fcab:1)}m {(c:3)}|p{(fcam:2), (cb:1)}p Conditional FP-treeConditional pattern")
38
Step 3: Recursively mine the conditional FP-tree {} f:3 c:3 a:3 m-conditional FP-tree Cond. pattern base of am: (fc:3) {} f:3 c:3 am-conditional FP-tree Cond. pattern base of cm: (f:3) {} f:3 cm-conditional FP-tree Cond. pattern base of cam: (f:3) {} f:3 cam-conditional FP-tree
 {} f:3 c:3 am-conditional FP-tree Cond. pattern base of cm: (f:3) {} f:3 cm-conditional FP-tree Cond. pattern base of cam: (f:3) {}")
39
Single FP-tree Path Generation Suppose an FP-tree T has a single path P The complete set of frequent pattern of T can be generated by enumeration of all the combinations of the sub-paths of P {} f:3 c:3 a:3 m-conditional FP-tree All frequent patterns concerning m m, fm, cm, am, fcm, fam, cam, fcam

40
Principles of Frequent Pattern Growth Pattern growth property Let be a frequent itemset in DB, B be 's conditional pattern base, and be an itemset in B. Then is a frequent itemset in DB iff is frequent in B. abcdef is a frequent pattern, if and only if abcde is a frequent pattern, and f is frequent in the set of transactions containing abcde

41
Why Is Frequent Pattern Growth Fast? Our performance study shows FP-growth is an order of magnitude faster than Apriori, and is also faster than tree-projection Reasoning No candidate generation, no candidate test Use compact data structure Eliminate repeated database scan Basic operation is counting and FP-tree building

42
FP-growth vs. Apriori: Scalability With the Support Threshold Data set T25I20D10K

43
FP-growth vs. Tree-Projection: Scalability with Support Threshold Data set T25I20D100K

44
Presentation of Association Rules (Table Form )
")
45
Visualization of Association Rule Using Plane Graph

46
Visualization of Association Rule Using Rule Graph

47
Iceberg Queries Icerberg query: Compute aggregates over one or a set of attributes only for those whose aggregate values is above certain threshold Example: select P.custID, P.itemID, sum(P.qty) from purchase P group by P.custID, P.itemID having sum(P.qty) >= 10 Compute iceberg queries efficiently by Apriori: First compute lower dimensions Then compute higher dimensions only when all the lower ones are above the threshold
 from purchase P group by P.custID, P.itemID having sum(")
Еще похожие презентации в нашем архиве:
















 objects.")



