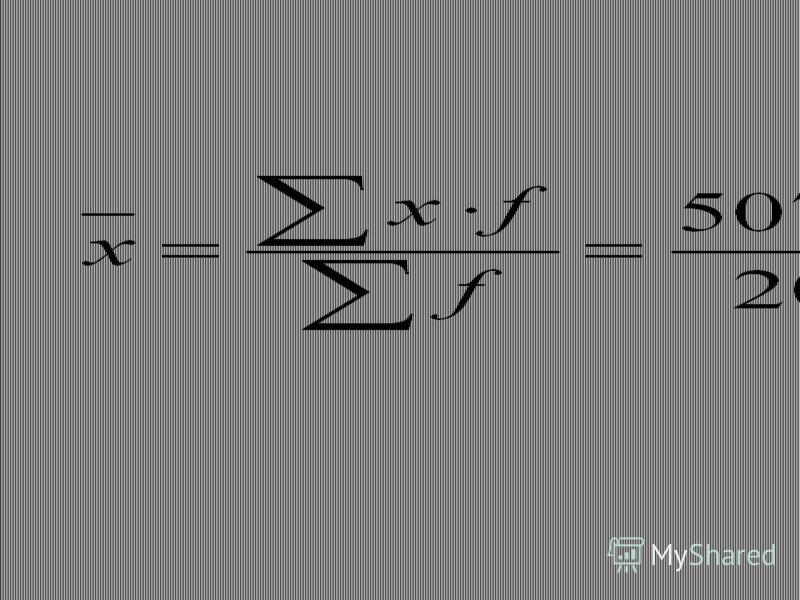Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

2
Chap 3-1 Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chapter 3 Describing Data: Numerical Statistics for Business and Economics 6 th Edition

3
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap 3-2 After completing this chapter, you should be able to: Compute and interpret the mean, median, and mode for a set of data Find the range, variance, standard deviation, and coefficient of variation and know what these values mean Apply the empirical rule to describe the variation of population values around the mean Explain the weighted mean and when to use it Explain how a least squares regression line estimates a linear relationship between two variables Chapter Goals

4
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap 3-3 Chapter Topics Measures of central tendency, variation, and shape Mean, median, mode, geometric mean Quartiles Range, interquartile range, variance and standard deviation, coefficient of variation Symmetric and skewed distributions Population summary measures Mean, variance, and standard deviation The empirical rule and Bienaymé-Chebyshev rule

5
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap 3-4 Chapter Topics Five number summary and box-and-whisker plots Covariance and coefficient of correlation Pitfalls in numerical descriptive measures and ethical considerations (continued)

6
Where we are Variables that generate raw data occur at random. So that useful information can be obtained about these variables, as shown in the previous chapters, raw data can be organized by using frequency distributions. Furthermore, organized data can be presented by using various graphs, observed during the last lecture

7
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap 3-6 Describing Data Numerically Arithmetic Mean Median Mode Describing Data Numerically Variance Standard Deviation Coefficient of Variation Range Interquartile Range Central TendencyVariation

8
Averages Statistical methods are used to organize and present data, and to summarize data. The most familiar of these methods is finding averages. For example, one may read that the average salary of top-managers is $5 mln and the salary of a Russian professor is less than $1,000

9
What is the Russian for average? существительное: среднее число; средняя величина; убыток от аварии судна; распределение убытка от аварии между владельцами; авария; среднее; среднее арифметическое глагол: составлять; равняться в среднем; выводить среднее число; составлять; выводить среднее число; распределять убытки; усреднять прилагательное: средний; обычный; нормальный

10
What is the Russian for mean? существительное: середина; среднее; средняя величина; среднее значение; среднее; среднее число; среднее арифметическое; средство, способ глагол: намереваться; иметь в виду; подразумевать; подразумеваться; думать; предназначать; предназначаться; значить; предвещать; иметь значение; означать прилагательное: средний; серединный; посредственный; плохой; слабый; скупой; скаредный; захудалый; жалкий; убогий; низкий; подлый; нечестный; низкого происхождения; придирчивый; недоброжелательный; бедный; скромный; смущающийся; трудный; неподдающийся

11
Average or Mean? Analyzing various texts we can summarize that the word average is used in general cases, in the discussion of medium size, and the word mean is used in special cases dealing with specific formulas and applications to find the average

12
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap 3-11 Measures of Central Tendency Central Tendency MeanMedian Mode Overview Midpoint of ranked values Most frequently observed value Arithmetic average

13
Arithmetic Mean Statistical methods are used to organize and present data, and to summarize data. The most familiar of these methods is finding averages. For example, one may read that the average salary of top-managers is $5 mln and the salary of a Russian professor is less than $1,000

14
Some quotes from Batueva In the book American averages by Mike Feinsilber and William B. Meed, the authors state: "Average" when you stop to think of it is a funny concept. Although it describes all of us it describes none of us... While none of us wants to be average American, we all want to know about him and her

15
Some quotes from Batueva The authors go on to give examples of averages: The average American man is five feet, nine inches tall; the average woman is five feet, 3.6 inches. The average American is sick in bed seven days a year missing five days of work. On the average day, 24 million people receive animal bites

16
Some quotes from Batueva By his or her 7th birthday, the average American will have eaten 14 steers, 1050 chickens, 3.5 lambs, and 25.2 hogs. In the above examples, the word average is ambiguous, since there are several different methods used to obtain an average. Loosely stated, the average means the center of the distribution or the most typical case. Measures of central tendency are also called measures of average and include the mean, mode and median

17
Some quotes from Batueva The mean is also known as arithmetic mean (or arithmetic average) and is the sum of the values divided by the total number of values in the sample or of the size of population. Fоr discrete (ungrouped) data the simple mean should be used
 and is the sum of the values divided by the total number of values in the sample or of the size of population. Fоr discrete (ungrouped) data the simple mean sh")
18
Logical formula The calculation of any average should start with determining a logical formula. Before multiplying, dividing, or adding anything, it is necessary to make the initial ratio of the average, otherwise known as a logical formula

19
The initial ratio of the average IRA

20
where A - The amount of the studied events in the population or sample: A is the summary absolute value; B – the size of population or sample: B is the number of units in the population or sample. IRA gives us the level of the studied events per unit of population or sample

21
Examples of IRA The average salary shows how much one employee earns. What do we take in the numerator and denominator of the IRR? A - amount of funds paid to all employees = wages & salaries fund; B - number of employees

22
Average salary The salary of the individual employee is the individual value. Wages & salaries fund is the summary value, and the average salary is an average

23
Examples of IRA The average price shows how much in average this good costs. What do we take in the numerator and denominator of the IRR? A – the turnover gained from the sale of goods; B - the total quantity of goods sold

24
Examples of IRA The average cost shows how much money was spent per unit of production. What do we take in the numerator and denominator of the IRR? A – the cost of production; B - the total quantity of goods produced = the quantity of output

25
Examples of IRA The average age shows the average number of years lived by the population under investigation; this indicator concerns not of necessarily animate objects - this may be the average age of cars, students, buildings, chickens, equipment. What do we take in the numerator and denominator of the IRR? A – the total number of years; B - the number of surveyed units

26
Examples of IRA Average lifespan: Life expectancy for people, service life, or average age of used equipment - shows the average number of years lived by investigated units, no matter living or inanimate objects they are. What do we take in the numerator and denominator of the IRR? A - total number of life (service) years; B - the number of surveyed units

27
Logical formula For a specific economic indicator we may form only one true logical formula

28
Types of averages Mathematicians proved that most averages we use, can be expressed in general terms, by the formula of average power (средней степенной)
")
29
The averages used in statistics relate to the class of power averages. The general formula of average power is as follows: _ where x k – average power of grade k; k – the exponent, which determines the type, or form of the average; х – the values of variants; n – the number of variants

30
If k =1, we get the simple arithmetic mean AM:

31
if k =2, we get the square mean SM:

32
in case of k =0, we get the geometric mean GM:

33
if k = -1, we have the harmonic mean HM:

34
Inequality concerning AM, GM, and HM Правило мажорантности A well known inequality concerning arithmetic, geometric, and harmonic means for any set of positive numbers is

35
It is easy to remember noting that the alphabetical order of the letters A, G, and H is preserved in the inequality. The higher exponent in the formula of average power, the greater the value of the average

36
Simple arithmetic mean SAM Simple arithmetic mean SAM is used when we have different variants without grouping. In the numerator, we find the amount of variants, in the denominator - the number of variants

37
Example 1.Productivity of 5 workers was 58, 50, 46, 44, 42 products per shift. Determine the average productivity of five workers. In this case, the solution is as follows:

38
Example 2 The miles-per-gallon fuel tests for ten automobiles are given below: 22.2, 23.7, 16.8, 19.7, 18.3, 19.7, 16.9, 17.2, 18.5, 21.0 Find the mean (the average miles-per-gallon)
")
39
Example 2 To find the average miles-per-gallon it is necessary to add all values and to divide the total sum by the number of automobiles: The average miles-per-gallon is 19.4 miles

40
Simple Arithmetic Mean SAM In this case, the simple arithmetic mean SAM was used and it could be calculated by the following equation: where n – the number of values in the sample or the size of population

41
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap 3-40 Simple Arithmetic Mean SAM The arithmetic mean (mean) is the most common measure of central tendency For a population of N values: For a sample of size n: Sample size Observed values Population size Population values
 is the most common measure of central tendency For a population of N values: For a sample of size n: Sample size")
42
Weighted arithmetic mean Weighted arithmetic mean WAM is used for grouped data. This is the most common power-average

43
Calculating the WAM for a frequency distribution

44
Example 3 For data in an ungrouped frequency distribution, the mean can be found as shown in the next example Example 3. The scores for 25 students on a 5- point quiz are shown below. Find the mean (the average score)
")
45
Example 3 Score, Number of students, frequency 010*1=0 121*2=2 262*6= *12=36 434*3=12 515*1=5 Total 25 67

46
Example 3 To find the average score it is necessary to calculate the total scores tor all students. For this, the multiplication between the score and the frequency To find the average score it is necessary to calculate the total scores tor all students. For this, the multiplication between the score and the frequency of each class should be made. Then, the sum of these multiplications must be found (see the last line in the table)

47
Example 3 Further, the total sum has to be divided by the number of students: The average score for 25 students on a 5-point quiz is 2.68 points

49
Weighted mean WAM In two last examples the weighted arithmetic mean was used and it could be calculated by the following formula: It is also used for data in grouped frequency distribution after transformation into ungrouped frequency distribution by dint of the midpoint.

50
Example 5 The following frequency distribution shows the amount of money (USD) 100 families spend for gasoline per month. Find the mean (the average amount of money)
 100 families spend for gasoline per month. Find the mean (the average amount of money)")
51
Example 5 Classes of families by the amount of money Number of families, Midpoint Total

52
The midpoint The procedure of finding the mean for grouped frequency distribution assumes that all of the raw data values in each class are equal to the midpoint of the class. In reality, this is not true, since the average of the raw data values in each class will not be exactly equal to the midpoint

53
Example 5 However, using this procedure will give an acceptable approximation of the mean, since some values fall above the midpoint and some values fall below the midpoint for each class. Average amount of money spent for gasoline by family is $42 per month

56
Modification of the WAM formula If f is a relative frequency (SR, a share in the population is given), the classic formula of weighted arithmetic mean WAM is not applicable, we can use its modification:
, the classic formula of weighted arithmetic mean WAM is not applicable, we can use its modification:")
57
Modification of the WAM formula where

58
Modification of the WAM formula In fact, we multiply variants by SR in shares

59
Conclusion For discrete data the simple arithmetic mean should be used. For ungrouped frequency distribution and for grouped frequency distribution the weighted arithmetic mean WAM should be used

60
Properties of the WAM The arithmetic mean has the following mathematical properties, which can be used in a task solution. These mathematical properties let us simplify the problem

61
The product of the arithmetic mean and the sum of frequencies is equal to the total volume of the studied events in the population (look at the IRA formula): 1 st property of the WAM
: 1 st property of the WAM")
62
2 nd property of the WAM The sum of deviations between the variants and the mean is equal to zero:

63
2. The sum of deviations between the variants and the mean is equal to zero This means, that in AM deviations from the average are mutually repaid

64
Properties of the arithmetic mean The properties 3 to 5 are used to simplify the calculation, when you need to calculate the average of unsuitable values

65
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap d property of the arithmetic mean If all variants multiply or divide by the same any constant B, the mean will increase or reduce by the same number of times:

66
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap th property of the arithmetic mean If all variants reduce or increase by definite amount A, then the mean will reduce or increase by the same amount:

67
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap th property of the arithmetic mean If all frequencies multiply and divide by the same any constant k, then the mean will not be changed:

68
Properties of the arithmetic mean If during the calculation of the WAM its properties have been used, we do not get a normal answer, that could be a transformed value. To get the normal WAM, you must make the reverse operations in reverse order

69
Simplified calculation of the arithmetic mean for a frequency distribution

70
is based on properties of the AM h – the interval width; c – one of the variants near the middle of the distribution (lying in the middle); А – a digital, a maximal multiple for all frequencies
; А – a digital, a maximal multiple for all frequencies")
72
h=20; c=250; f=f'; A=1

73
Example 7 The following data represent the grouping of workers by size of payment: ClassesNumber of workers, More than Total:100 Find the average size of payment, using the mathematical properties of the mean Chap 3-72

74
Example 7 Chap 3-73 Transform the grouped frequency distribution into ungrouped frequency distribution calculating the midpoint (column 3). After that, using the property #4, each item could be reduced by the same constant A. Digital A can be anyone, however it is recommended to accept it equal to the variant with maximal frequency (column 4)
. After that, using the property #4, each item could be reduced by the same constant A. Digital A can be anyone,")
75
Example 7 Chap 3-74 On the basis of the property #3, reduced variants should be divided by the constant B, which can be anyone too. But it is recommended to accept В equal to the width of classes (column 5). The next table shows the procedure of solving the problem
. The next table shows the procedure of solv")
76
Example 7 Classes, USD Num-ber of wor- kers, Mid- point More than Total:

77
Example 7 We have now new variants, which can be symbolized Since changing of the variants involved changing of the mean, it is necessary to get back the actual magnitude of the mean. Using the property #5, all frequencies were divided by k=5, because 5 is the maximal multiple (column 6)

78
Example 7 New frequencies are symbolized According to the property #5, changing of frequencies does not entail changing of the mean. Thus the formula of the mean will look as follows, using the mathematical properties: The average wage is $820 per worker.

79
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap 3-78 Arithmetic Mean The most common measure of central tendency Mean = sum of values divided by the number of values Affected by extreme values (outliers) (continued) Mean = Mean = 4
 (continued) 0 1")
80
Arithmetic Mean The arithmetic mean, as a single number representing a whole data set, has important advantages. First, its concept is familiar to most people and intuitively clear. Second, every data set has a mean. It is a measure that can be calculated, and it is unique because every data set has one and only one mean. Finally, the mean is useful for performing statistical procedure such as comparing the means from several data sets

81
Harmonic Mean HM The harmonic mean HM is defined as the number of values divided by the sum of the reciprocals of each value. The equations of the HM are shown below: simple harmonic mean:

82
Harmonic Mean HM weighted harmonic mean: where W i =x i f i.

83
Harmonic Mean HM HM is the reciprocal of the arithmetic mean: one can get the arithmetic mean as number 1, divided by the harmonic mean and vice versa. There are simple and weighted HMs. The weighted formula of HM is used more often

84
Harmonic Mean HM In the case of HM, frequencies are not known, but we know the total sum of the values. In fact, the arithmetic mean and the harmonic mean are applied in the same cases, but under different data sets. And so, before the choice of the mean equation it is necessary to construct the logical (economic) formula

85
HM is applied when the volumes of investigated variants are used as weights. Sometimes the problem arises: what formula should be used - the harmonic mean HM or arithmetic mean AM? The answer is as follows: Fits the formula, in which both the numerator and denominator would have values with an economic meaning

86
AM or HM ? The tip: If the initial information gives an averaged value (variant) and the denominator of the logical formula, the AM is used. If variant and the numerator of the logical formula are given, the HM is implemented
 and the denominator of the logical formula, the AM is used. If variant and the numerator of the logical formula are given, the HM is implemented")
87
AM or HM ? In other words: If the numerator of the IRA is unknown, well use AM. If the denominator of the IRA is unknown, the HM should be used

88
Example 8

90
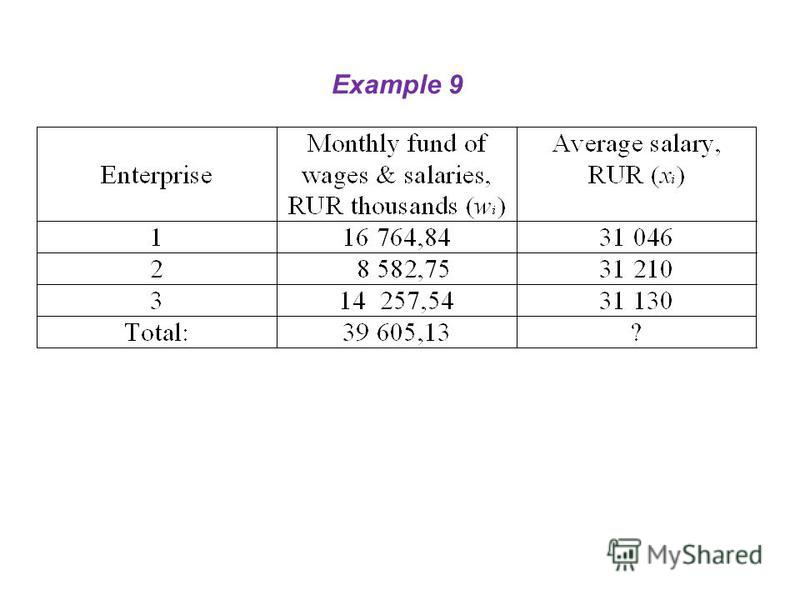
Example 9

92
Example 10 A carpenter buys $500 worth of nails at $50 per pound and $500 worth of nails at $10 per pound. Find the mean (average price of a pound of nails). For task solution we have to define how the average price can be found. Construct the logical formula expressing the relation between price, and worth:
. For task solution we have to define how the average price can be found. Construct the logica")
93
Example 10 In this case, the total worth is known, but the number of pounds is not known. Therefore, the number of pounds could be counted by the ratio between total worth and price: The average price per pound of nails is $ The logical equation allows us to correctly choose the mean equation not breaking the relation of economic processes

94
Example 11 Below is the data about wages: #of workshop Base monthReporting month Salary per person, thousand rubles, Xj Number of personnel, people, fj Salary per person, thousand rubles, Xj Wages fund, thousand rubles, Wi Find the average salary per person in each month

95
Example 11 First, construct the logical formula, describing the relation between salary, wages fund, and the number of personnel:

96
Example 11 For the base month Wages fund is not known, but the number of personnel is known. Wages fund is the total sum of values Wi and could be defined by multiplication between salary per person (variants xi) and the number of personnel (frequencies fi). Thus, logical formula will be as follows:
 and the number of personnel (frequenc")
97
Example 11 Using this logical formula, the average salary for the base month could be calculated: To calculate the average salary the weighted arithmetic mean was used:

98
Example 11 For the reporting month, Wages fund is known, but the number of personnel is not known. The number of personnel could be expressed by dividing Wages fund by the salary per person. Thus, the logical formula has been transformed in the following way:

99
Example 11 Using this transformation of the initial logical formula, the average salary could be calculated on the basis of the weighted harmonic mean:

100
Once more AM or HM ? The accuracy of the choice of the mean equations is rule-based: If the numerator of the logical formula is unknown, the arithmetic mean should be used. If the denominator of the logical formula is unknown the harmonic mean should be used

101
The geometric mean GM Sometimes when we are dealing with quantities that change over a period of time, we need to know an average rate of change, such as an average growth rate over a period of several years. In such cases, the arithmetic mean AM and the harmonic mean HM are inappropriate, because they give wrong answers. What we need to find is the geometric mean GM. The geometric mean GM is defined as the n th root of the product of n values

102
The geometric mean GM The formula of the simple geometric mean GM is: The geometric mean is useful for finding the average of percentages, ratios, indexes or growth rates

103
Example 12 The growth rate of the Living Life Insurance Corporation for the part three years was 35%, 24%, and 18%. Find the average growth rate. First, it is necessary to transform the growth rate into growth factor, using the following equation:

104
Example 12 Further the geometric mean can be applied: The average growth rate is 25.47% per year

105
The geometric mean GM The geometric mean could be applied when the data do to have large spread. Let us suppose, you want to calculate the average winning amount between maximal and minimal winnings amounts. n of the geometric mean is more justified:

106
Example 13 The geometric mean could be applied when the data do to have large spread. Let us suppose, you want to calculate the average winning amount between maximal and minimal winnings amounts. Example 13. Minimal winning amount $1000 and maximal winning amount $100,000. Find the average winning amount

107
Example 13 The raw data have big difference, and so, the application of the arithmetic mean will be incorrect. In this case, the application of the geometric mean is more justified: The average winning amount is $10,000

108
Weighted geometric mean WGM For analysis of time series the weighted geometric mean could be used. The formula is shown below: The application of the weighted geometric mean will be needed while solving problems on time series

109
The quadratic (square) mean QM A useful mean for physical sciences is the quadratic mean, which it found by taking the square root of the sum of the average of the squares of each value. There arc two kinds of the quadratic mean: the simple quadratic mean and the weighted quadratic mean: the simple quadratic mean;
 mean QM A useful mean for physical sciences is the quadratic mean, which it found by taking the square root of the sum of the average of the squares of each value. There arc two kinds of the quadratic mean: the simple quadratic")
110
The quadratic (square) mean QM the weighted quadratic mean. The quadratic mean is applied when the measures of dispersion are calculated
 mean QM the weighted quadratic mean. The quadratic mean is applied when the measures of dispersion are calculated")
111
Chronological mean TM This mean formula is applied to the number of moment indicators, especially in time series:

112
Chronological mean TM Take half of the first and last values, plus all values that are in the middle of the series, the amount received divide by the number of moment indicators minus 1

113
Chronological mean TM TM is widely used in time series analysis, in socio-economic statistics to determine the average population and average size of the fund, as well as other indicators, calculated at certain points in time

114
Chronological mean TM If calculating the average for two moment indicators, the formula for chronological mean TM transforms into the formula of simple arithmetic mean AM:

115
Structural averages Using the average power for the analysis of the distribution is not enough. Structural averages are used for initial analysis of the distribution of units in the population

116
Structural averages Out of numerous list of structural averages well discuss mode, median, quartile, decile, and percentile

117
Mode - the value of the variant occurring in the population the largest number of times. In everyday life the word mode" actually has the opposite meaning as fashion Mode Mo

118
Mode is the most common variant of frequency distribution. For a discrete series this is the value, which corresponds to the highest frequency Mode Mo

119
The mode is the value that is repeated most often in the data set. A data set can have more than one mode or no mode at all. If we analyze a discrete series and there are several variants with the highest frequency (which is quite rare), then the mode is defined as the arithmetic average of all the modal variants
, then the mod")
120
Mode Mo The mode is the value that is repeated most often in the data set. A data set can have more than one mode or no mode at all. The value that occurs most often in a data set is called the mode The mode can be defined only for ungrouped frequency distribution and grouped frequency distribution. The mode for ungrouped frequency distribution could be defined by sight, by definition, using the most frequency

121
Example 4

122
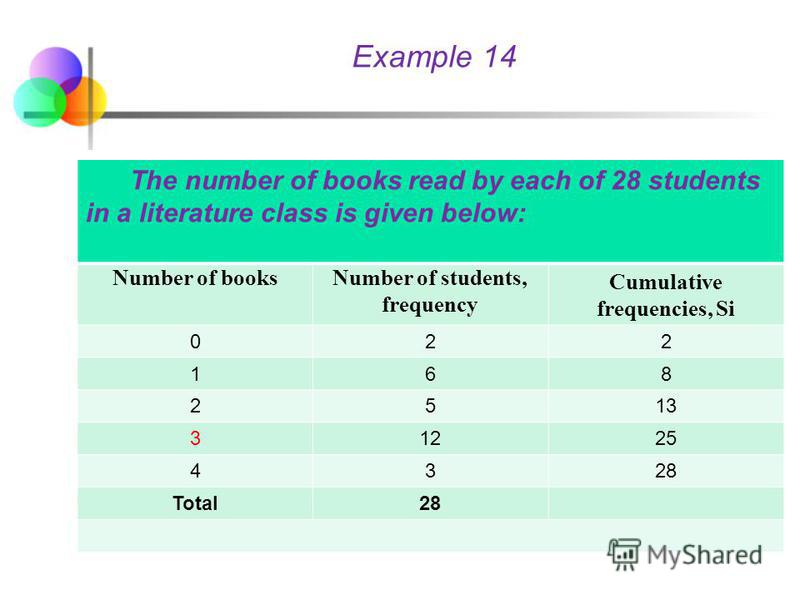
Example 14 The number of books read by each of the 28 students in a literature class is given below:

123
Example 14 The number of books read by each of 28 students in a literature class is given below: Number of booksNumber of students, frequency The most frequency Total28 The most frequency is 12, it means the mode is 2 books. Thus, the most students have read only two books

124
The mode for grouped frequency distribution can be defined using the following equation. It is used for interval frequency distribution with equal interval widths : where x M о - lower boundary of the modal class; h М о - width of the modal class; f М о - frequency of the modal class; f М о-1 - frequency of the pre-modal class; f М о+1 - frequency of the after-modal class

127
Finding the modal interval First, it is necessary to define the modal class by definition, using the most frequency. Therefore, the most frequency is 25 and it conforms to the class which is detected as the modal interval

128
Example 7 The following data represent the grouping of workers by size of payment: The size of payment, USDNumber of workers,% More than Total:100 Find the mode Chap 3-127

129
Thus, the majority of workers have the salary in the amount of $833.3

130
Mode Mo If the modal interval of the first or the last, the missing frequency (or pre-modal or after-modal) is taken to be zero
 is taken to be zero")
131
The mode on a graph The mode can be defined using the histogram. For this, it is necessary to select the highest bar, and then connect its right-wing angle with right- wing angle of previous bar. Further, connect left- wing angle of the highest bar with left-wing angle of the next bar. From the point of intersection of two segments, drop a perpendicular on the X-line. The point of intersection of perpendicular and abscissa axis is called the mode

133
The mode on a graph To determine the mode of a discrete series the frequency polygon is drawn. The distance from the vertical axis to the highest point is the graphics mode

134
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Median In an ordered list, the median is the middle number (50% above, 50% below) Not affected by extreme values Median = Median = 3
 Not affected by extreme values 0 1 2 3 4 5 6 7 8 9 10 Median = 3 0 1 2 3 4 5 6 7 8 9")
135
Median The median is the measure of central tendency different from any of means. The median is a single value from the data set that measures the central item in the data. This single item is the middlemost or most central item in the set of numbers. Half of the items lie above this point, and the other half lie below it. The median is the midpoint of the data array For calculating the median the data must be ascended or descended by order

136
Median Me Me is the central, middle value of a population. Me – the value of a variant located in the middle of the ordered list. Me is the variant, which lies in the middle of the frequency distribution and divides it into two equal parts. In the discrete list Me is determined by definition, in the interval frequency distribution – by the formula

137
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Finding the Median The location of the median: If the number of values is odd, the median is the middle number If the number of values is even, the median is the average of the two middle numbers Note that is not the value of the median, only the position of the median in the ranked data

138
Finding the Median If a discrete list contains an odd number of values, Me is the only value, to the right and the left of which there is the same number of values:

139
Example 15 Find the median for the ages of seven preschool children. The ages are 2, 3, 4, 2, 3, 5 and 5. First it is necessary to ascend the data: 2, 2, 3, 3, 4, 5, 5. According to the equation, the median is the (7+l)/2=4 th item in the array and conforms to 3 years. Thus, you can say, half of the children are under 3 and the other half of them are over 3
/2=4 th item in the array and c")
140
Median For ungrouped data the median can be defined in the following way. If the data set contains an odd number of items, the middle item of the array is the median. If there is an even number of items, the median is the average of the two middle items and can be calculated using the equation from the next slide

141
Finding the Median If a discrete list contains an even number of values, there are two values, to the right and to the left of which there is the same number of values. Me is the arithmetic mean of these two values:

142
Example 16 The ages of ten college students are given below. Find the median: 18, 24, 20, 35, 19, 23, 26, 23, 19, 20. The data set contains the even number of items. Set the data in the ascending order: 18, 19, 19, 20, 20, 23, 23, 24, 26, 35. Using the equation, the median is the (10+1)/2=5.5 th item in the data set. In other words, the median lies between the 5 th and the 6 th items. Thus, the median is: Me= ( )/2= 21.5 years Therefore, half of the students are under 21.5 and the other half of the students are over 21.5 years old

143
Finding the Median For ungrouped frequency distribution the median Me can be defined using the cumulative frequencies

144
The golden rule Для дискретного ряда медианой является та варианта, для которой накопленная частота впервые превышает половину от суммы частот For the discrete frequency distribution the median is the value, for which the cumulative frequency for the first time is more than the half of the total frequencies

146
Example 14 The number of books read by each of 28 students in a literature class is given below: Number of booksNumber of students, frequency Cumulative frequencies, Si Total28

147
Example 14 To locate the middle point, divide n by 2, which gives 28/2=14. Then locate the point where 14 values would fall below and 14 values would fall above. The 14 th item falls in the fourth class and conforms to 3 books. Me = 3 books. It means, half of the students have read less than 3 books and the other half have read more than 3 books Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap 3-146

148
For grouped frequency distribution the median can be defined using the following equation: where x Ме - lower boundary of the median class; h Ме - width of the median class; f Ме - frequency of the median class; S Ме-1 - cumulative frequencies of the class immediately preceding the median class; - the sum of all frequencies (the size of population, the size of sampling)

149
Finding the Median The median class can be defined following the definition and the Golden Rule: we use the cumulative frequencies, in the median interval they are for the first time bigger than the ½ of the sum of all frequencies

151
This means that half of workers have labor productivity which is less than m, while the other half has productivity more than m

152
Example 7 The following data represent the grouping of workers by size of payment: The size of payment, USDNumber of workers,% Cumulative frequencies, Si More than Total:100 Find the median Chap 3-151

153
First, it is necessary to divide the sum of all frequencies by 2 to find the halfway point: 100/2=50. Further, let us find the class that contains the 50 th value. This class is called the median class and it contains the median. The median class is $ Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap 3-152

154
Thus, half of workers have the size of payment less than $820 and the other half of workers have the size of payment more than $820

155
The median can be defined using the ogive. For this, it is recommended to select the point on the Y-line conforming to ½ of all frequencies. From this point the parallel to X-line should be drawn. From the point of intersection of parallel and ogive it is necessary to drop a perpendicular on the abscissa axis. The point of intersection of perpendicular and X-line is named the median. The next slide shows this procedure with the help of cumulative frequency graph

157
Мо & Ме In practical calculations of Mo and Me their values may be far removed from each other. To better reflect the nature of distribution statisticians use other structural averages

158
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Mode A measure of central tendency Value that occurs most often Not affected by extreme values Used for either numerical or categorical data There may may be no mode There may be several modes Mode = No Mode

159
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Five houses on a hill by the beach Review Example House Prices: $2,000, , , , ,000

160
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Review Example: Summary Statistics Mean: ($3,000,000/5) = $600,000 Median: middle value of ranked data = $300,000 Mode: most frequent value = $100,000 House Prices: $2,000, , , , ,000 Sum 3,000,000
 = $600,000 Median: middle value of ranked data = $300,000 Mode: most frequent value = $100,000 House Prices: $")
161
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Mean is generally used, unless extreme values (outliers) exist Then median is often used, since the median is not sensitive to extreme values. Example: Median home prices may be reported for a region – less sensitive to outliers Which measure of location is the best?
 exist Then median is often used, since the median is not sensitive to extreme values. Example: Median home pr")
162
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Shape of a Distribution Describes how data are distributed Measures of shape Symmetric or skewed Mean = Median Mean < Median Median < Mean Right-Skewed Left-SkewedSymmetric

163
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Same center, different variation Measures of Variability Variation Variance Standard Deviation Coefficient of Variation RangeInterquartile Range Measures of variation give information on the spread or variability of the data values.

164
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Range Simplest measure of variation Difference between the largest and the smallest observations: Range = X largest – X smallest Range = = 13 Example:

165
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Ignores the way in which data are distributed Sensitive to outliers Range = = Range = = 5 Disadvantages of the Range 1,1,1,1,1,1,1,1,1,1,1,2,2,2,2,2,2,2,2,3,3,3,3,4,5 1,1,1,1,1,1,1,1,1,1,1,2,2,2,2,2,2,2,2,3,3,3,3,4,120 Range = = 4 Range = = 119

166
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Interquartile Range Can eliminate some outlier problems by using the interquartile range Eliminate high- and low-valued observations and calculate the range of the middle 50% of the data Interquartile range = 3 rd quartile – 1 st quartile IQR = Q 3 – Q 1

167
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Interquartile Range Median (Q2) X maximum X minimum Q1Q3 Example: 25% 25% Interquartile range = 57 – 30 = 27
 X maximum X minimum Q1Q3 Example: 25% 25% 12 30 45 57 70 Interquartile range = 57 – 30 = 27")
168
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Quartiles Quartiles split the ranked data into 4 segments with an equal number of values per segment 25% The first quartile, Q 1, is the value for which 25% of the observations are smaller and 75% are larger Q 2 is the same as the median (50% are smaller, 50% are larger) Only 25% of the observations are greater than the third quartile Q1Q2Q3

169
Это варианты, которые делят ранжированную совокупность на четыре равные части: Q 1 1:3; Q 2 2:2 (Q 2 =Ме); Q 3 3:1
; Q 3 3:1")
170
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Quartile Formulas Find a quartile by determining the value in the appropriate position in the ranked data, where First quartile position: Q 1 = 0.25(n+1) Second quartile position: Q 2 = 0.50(n+1) (the median position) Third quartile position: Q 3 = 0.75(n+1) where n is the number of observed values
 Second quart")
171
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap (n = 9) Q 1 = is in the 0.25(9+1) = 2.5 position of the ranked data so use the value half way between the 2 nd and 3 rd values, so Q 1 = 12.5 Quartiles Sample Ranked Data: Example: Find the first quartile
 Q 1 = is in the 0.25(9+1) = 2.5 position of the ranked data so use the value half way between the 2 nd and 3 rd values, so Q 1 = 12.5 Quartiles Sample Ranked")
172
Квартили Первый (нижний) квартиль отсекает от совокупности ¼ часть единиц с минимальными значениями, а третий (верхний) отсекает ¼ часть единиц с максимальными значениями
 квартиль отсекает от совокупности ¼ часть единиц с минимальными значениями, а третий (верхний) отсекает ¼ часть единиц с максимальными значениями")
173
Квартили Мы как бы отбрасываем нетипичные, случайные значения признака. С помощью квартилей мы определяем границы, где находятся 50% единиц, наиболее характерные для этой совокупности

174
Для расчета Q 1 (первого квартиля) используется следующая формула: где x Q 1 - начало интервала, содержащего 1-й квартиль; h Q 1 - величина интервала, содержащего 1-й квартиль; S Q накопленная частота предшествующего интервала; f Q 1 - частота интервала, содержащего Q 1
 используется следующая формула: где x Q 1 - начало интервала, содержащего 1-й квартиль; h Q 1 - величина интервала, содержащего 1-й квартиль; S Q 1 - 1 - накопленная частота предшествующего интервала; f Q 1 - частот")
175
Интервалом, содержащим Q 1, является тот интервал, для которого накопленная частота впервые превышает ¼ от суммы частот

177
Это означает, что ¼ рабочих имеет производительность труда меньше, чем 234м., а ¾ имеет производительность труда больше

179
Для расчета Q 3 используется формула: Все обозначения аналогичны Q 1. Интервалом, содержащим Q 3, является тот интервал, для которого накопленная частота впервые превышает ¾ от суммы частот

182
Децили - это варианты, которые делят ранжированную совокупность на 10 равных частей

183
Общая формула для расчета децилей: где x D i - начало интервала,содержащего i-й дециль; h D i - величина интервала, содержащего i-й дециль; f D i - частота интервала, содержащего D i ; S D i -1 - накопленная частота предшествующего интервала

184
Интервалом, содержащим D i,является тот интервал, для которого накопленная частота впервые превышает i/10 от суммы частот

186
Пример: Это означает что, 60% рабочих имеют производительность труда меньше 259,6м, а 40% - больше

187
Применение децилей Пример - децильный коэффициент дифференциации населения. Население делится на 10 частей по уровню дохода. Берут первые 10% и последние 10%. Считают, что средний доход последней группы не должен быть больше, чем в 10 раз среднего дохода первой группы. В России официально это превышение составляет раз, неофициально – 20 и более раз

188
Перцентиль П делит ранжированную совокупность на 100 равных частей. Формулы аналогичны формулам медианы, квартиля и дециля

189
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Average of squared deviations of values from the mean Population variance: Population Variance Where = population mean N = population size x i = i th value of the variable x

190
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Average (approximately) of squared deviations of values from the mean Sample variance: Sample Variance Where = arithmetic mean n = sample size X i = i th value of the variable X
 of squared deviations of values from the mean Sample variance: Sample Variance Where = arithmetic mean n = sample size X i = i th value of the")
191
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Population Standard Deviation Most commonly used measure of variation Shows variation about the mean Has the same units as the original data Population standard deviation:

192
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Sample Standard Deviation Most commonly used measure of variation Shows variation about the mean Has the same units as the original data Sample standard deviation:

193
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Calculation Example: Sample Standard Deviation Sample Data (x i ) : n = 8 Mean = x = 16 A measure of the average scatter around the mean
 : 10 12 14 15 17 18 18 24 n = 8 Mean = x = 16 A measure of the average scatter around the mean")
194
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Measuring variation Small standard deviation Large standard deviation

195
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Comparing Standard Deviations Mean = 15.5 s = Data B Data A Mean = 15.5 s = Mean = 15.5 s = Data C

196
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Advantages of Variance and Standard Deviation Each value in the data set is used in the calculation Values far from the mean are given extra weight (because deviations from the mean are squared)

197
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap For any population with mean μ and standard deviation σ, and k > 1, the percentage of observations that fall within the interval [μ + kσ] Is at least Chebyshevs Theorem
![Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap 3-196 For any population with mean μ and standard deviation σ, and k > 1, the percentage of observations that fall within the interval [μ + kσ] Is at least Chebyshevs Theor](http://images.myshared.ru/17/1048576/slide_197.jpg "Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap 3-196 For any population with mean μ and standard deviation σ, and k > 1, the percentage of observations that fall within the interval [μ + kσ] Is at least Chebyshevs Theor")
198
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Regardless of how the data are distributed, at least (1 - 1/k 2 ) of the values will fall within k standard deviations of the mean (for k > 1) Examples: (1 - 1/1 2 ) = 0% ……..... k=1 (μ ± 1σ) (1 - 1/2 2 ) = 75% … k=2 (μ ± 2σ) (1 - 1/3 2 ) = 89% ………. k=3 (μ ± 3σ) Chebyshevs Theorem withinAt least (continued)
 of the values will fall within k standard deviations of the mean (for k > 1) Examples: (1 - 1/1 2 )")
199
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap If the data distribution is bell-shaped, then the interval: contains about 68% of the values in the population or the sample The Empirical Rule 68%

200
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap contains about 95% of the values in the population or the sample contains about 99.7% of the values in the population or the sample The Empirical Rule 99.7%95%

201
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Coefficient of Variation Measures relative variation Always in percentage (%) Shows variation relative to mean Can be used to compare two or more sets of data measured in different units
 Shows variation relative to mean Can be used to compare two or more sets of data measure")
202
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Comparing Coefficient of Variation Stock A: Average price last year = $50 Standard deviation = $5 Stock B: Average price last year = $100 Standard deviation = $5 Both stocks have the same standard deviation, but stock B is less variable relative to its price

203
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Using Microsoft Excel Descriptive Statistics can be obtained from Microsoft ® Excel Use menu choice: tools / data analysis / descriptive statistics Enter details in dialog box

204
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Using Excel Use menu choice: tools / data analysis / descriptive statistics

205
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Enter dialog box details Check box for summary statistics Click OK Using Excel (continued)
")
206
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Excel output Microsoft Excel descriptive statistics output, using the house price data: House Prices: $2,000, , , , ,000

207
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Weighted Mean The weighted mean of a set of data is Where w i is the weight of the i th observation Use when data is already grouped into n classes, with w i values in the i th class

208
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Approximations for Grouped Data Suppose a data set contains values m 1, m 2,..., m k, occurring with frequencies f 1, f 2,... f K For a population of N observations the mean is For a sample of n observations, the mean is

209
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Approximations for Grouped Data Suppose a data set contains values m 1, m 2,..., m k, occurring with frequencies f 1, f 2,... f K For a population of N observations the variance is For a sample of n observations, the variance is

210
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap The Sample Covariance The covariance measures the strength of the linear relationship between two variables The population covariance: The sample covariance: Only concerned with the strength of the relationship No causal effect is implied

211
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Covariance between two variables: Cov(x,y) > 0 x and y tend to move in the same direction Cov(x,y) < 0 x and y tend to move in opposite directions Cov(x,y) = 0 x and y are independent Interpreting Covariance
 > 0 x and y tend to move in the same direction Cov(x,y) < 0 x and y tend to move in opposite directions Cov(x,y) = 0 x and")
212
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Coefficient of Correlation Measures the relative strength of the linear relationship between two variables Population correlation coefficient: Sample correlation coefficient:

213
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Features of Correlation Coefficient, r Unit free Ranges between –1 and 1 The closer to –1, the stronger the negative linear relationship The closer to 1, the stronger the positive linear relationship The closer to 0, the weaker any positive linear relationship

214
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Scatter Plots of Data with Various Correlation Coefficients Y X Y X Y X Y X Y X r = -1 r = -.6r = 0 r = +.3 r = +1 Y X r = 0

215
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Using Excel to Find the Correlation Coefficient Select Tools/Data Analysis Choose Correlation from the selection menu Click OK...

216
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Using Excel to Find the Correlation Coefficient Input data range and select appropriate options Click OK to get output (continued)
")
217
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Interpreting the Result r =.733 There is a relatively strong positive linear relationship between test score #1 and test score #2 Students who scored high on the first test tended to score high on second test

218
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Obtaining Linear Relationships An equation can be fit to show the best linear relationship between two variables: Y = β 0 + β 1 X Where Y is the dependent variable and X is the independent variable

219
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Least Squares Regression Estimates for coefficients β 0 and β 1 are found to minimize the sum of the squared residuals The least-squares regression line, based on sample data, is Where b 1 is the slope of the line and b 0 is the y- intercept:

220
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap Chapter Summary Described measures of central tendency Mean, median, mode Illustrated the shape of the distribution Symmetric, skewed Described measures of variation Range, interquartile range, variance and standard deviation, coefficient of variation Discussed measures of grouped data Calculated measures of relationships between variables covariance and correlation coefficient

Еще похожие презентации в нашем архиве: