Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

1
метод наименьших квадратов

2
ОСНОВНЫЕ СТАТИСТИКИ

3
метод наименьших квадратов с линейными ограничениями

6
УСЛОВНАЯ ОПТИМИЗАЦИЯ

13
метод наименьших квадратов с линейными ограничениями

14
ПРОВЕРКА ГИПОТЕЗЫ О ЛИНЕЙНЫХ ОГРАНИЧЕНИЯХ

21
ПОСТРОЕНИЕ ДОВЕРИТЕЛЬНЫХ ОБЛАСТЕЙ

22
метод наименьших квадратов с линейными ограничениями

27
. reg S ASVABC Source | SS df MS Number of obs = F( 1, 568) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ASVABC | _cons | F TESTS OF GOODNESS OF FIT 34 We will illustrate the test with an educational attainment example. Here is S regressed on ASVABC using Data Set 21. We make a note of the residual sum of squares.
 = 284.89 Model | 1153.80864 1 1153.80864 Prob > F = 0.0000 Residual | 2300.43873 568 4.05006818 R-squared = 0.3340 ---------+--------------------")
28
. reg S ASVABC SM SF Source | SS df MS Number of obs = F( 3, 566) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ASVABC | SM | SF | _cons | F TESTS OF GOODNESS OF FIT 35 Now we have added the highest grade completed by each parent. Does parental education have a significant impact? Well, we can see that a t test would show that SF has a highly significant coefficient, but we will perform the F test anyway. We make a note of RSS.
 = 110.83 Model | 1278.24153 3 426.080508 Prob > F = 0.0000 Residual | 2176.00584 566 3.84453329 R-squared = 0.3700 ---------+--------------")
29
F TESTS OF GOODNESS OF FIT F(cost, d.f. remaining) = improvementcost remaining unexplained degrees of freedom remaining 41 The critical value of F(2,120) at the 0.1% level is The critical value of F(2,566) must be lower, so we reject H 0 and conclude that the parental education variables do have significant joint explanatory power.
 = improvementcost remaining unexplained degrees of freedom remaining 41 The critical value of F(2,120) at the 0.1% level is 7.32. The critical value of F(2,566) must be lower, so we reject H 0 and co")
31
метод наименьших квадратов с линейными ограничениями

32
F TESTS OF GOODNESS OF FIT 10 ESS / TSS is equal to R 2 and RSS / TSS is equal to (1 - R 2 ). (For proofs, see the last sequence in Chapter 3.)
. (For proofs, see the last sequence in Chapter 3.)")
35
. reg S ASVABC SM SF Source | SS df MS Number of obs = F( 3, 566) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ASVABC | SM | SF | _cons | F TESTS OF GOODNESS OF FIT 18 The critical value for F(3,566) is not given in the F tables, but we know it must be lower than F(3,120), which is given. At the 0.1% level, this is Hence we easily reject H 0 at the 0.1% level.
 = 110.83 Model | 1278.24153 3 426.080508 Prob > F = 0.0000 Residual | 2176.00584 566 3.84453329 R-squared = 0.3700 ---------+--------------")
36
. reg S ASVABC SM SF Source | SS df MS Number of obs = F( 3, 566) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ASVABC | SM | SF | _cons | F TESTS OF GOODNESS OF FIT 19 This result could have been anticipated because both ASVABC and SF have highly significant t statistics. So we knew in advance that both 2 and 4 were non-zero.
 = 110.83 Model | 1278.24153 3 426.080508 Prob > F = 0.0000 Residual | 2176.00584 566 3.84453329 R-squared = 0.3700 ---------+--------------")
37
. reg S ASVABC SM SF Source | SS df MS Number of obs = F( 3, 566) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ASVABC | SM | SF | _cons | F TESTS OF GOODNESS OF FIT 20 It is unusual for the F statistic not to be significant if some of the t statistics are significant. In principle it could happen though. Suppose that you ran a regression with 40 explanatory variables, none being a true determinant of the dependent variable.
 = 110.83 Model | 1278.24153 3 426.080508 Prob > F = 0.0000 Residual | 2176.00584 566 3.84453329 R-squared = 0.3700 ---------+--------------")
38
. reg S ASVABC SM SF Source | SS df MS Number of obs = F( 3, 566) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ASVABC | SM | SF | _cons | F TESTS OF GOODNESS OF FIT 21 Then the F statistic should be low enough for H 0 not to be rejected. However, if you are performing t tests on the slope coefficients at the 5% level, with a 5% chance of a Type I error, on average 2 of the 40 variables could be expected to have "significant" coefficients.
 = 110.83 Model | 1278.24153 3 426.080508 Prob > F = 0.0000 Residual | 2176.00584 566 3.84453329 R-squared = 0.3700 ---------+--------------")
39
. reg S ASVABC SM SF Source | SS df MS Number of obs = F( 3, 566) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ASVABC | SM | SF | _cons | F TESTS OF GOODNESS OF FIT 22 The opposite can easily happen, though. Suppose you have a multiple regression model which is correctly specified and the R 2 is high. You would expect to have a highly significant F statistic.
 = 110.83 Model | 1278.24153 3 426.080508 Prob > F = 0.0000 Residual | 2176.00584 566 3.84453329 R-squared = 0.3700 ---------+--------------")
40
. reg S ASVABC SM SF Source | SS df MS Number of obs = F( 3, 566) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ASVABC | SM | SF | _cons | F TESTS OF GOODNESS OF FIT 23 However, if the explanatory variables are highly correlated and the model is subject to severe multicollinearity, the standard errors of the slope coefficients could all be so large that none of the t statistics is significant.
 = 110.83 Model | 1278.24153 3 426.080508 Prob > F = 0.0000 Residual | 2176.00584 566 3.84453329 R-squared = 0.3700 ---------+--------------")
41
. reg S ASVABC SM SF Source | SS df MS Number of obs = F( 3, 566) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ASVABC | SM | SF | _cons | F TESTS OF GOODNESS OF FIT 24 In this situation you would know that your model is a good one, but you are not in a position to pinpoint the contributions made by the explanatory variables individually.
 = 110.83 Model | 1278.24153 3 426.080508 Prob > F = 0.0000 Residual | 2176.00584 566 3.84453329 R-squared = 0.3700 ---------+--------------")
42
ПРОВЕРКА ГИПОТЕЗЫ С ОДНИМ ЛИНЕЙНЫМ ОГРАНИЧЕНИЕМ

44
. reg S ASVABC SM SF Source | SS df MS Number of obs = F( 3, 566) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ASVABC | SM | SF | _cons | F TESTS OF GOODNESS OF FIT 35 Now we have added the highest grade completed by each parent. Does parental education have a significant impact? Well, we can see that a t test would show that SF has a highly significant coefficient, but we will perform the F test anyway. We make a note of RSS.
 = 110.83 Model | 1278.24153 3 426.080508 Prob > F = 0.0000 Residual | 2176.00584 566 3.84453329 R-squared = 0.3700 ---------+--------------")
45
F TESTS OF GOODNESS OF FIT 45 The F test has the usual structure. We will illustrate it with an educational attainment model where S depends on ASVABC and SM in the original model and on SF as well in the revised model. F(cost, d.f. remaining) = improvementcost remaining unexplained degrees of freedom remaining
 = impr")
46
. reg S ASVABC SM Source | SS df MS Number of obs = F( 2, 567) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ASVABC | SM | _cons | F TESTS OF GOODNESS OF FIT 46 Here is the regression of S on ASVABC and SM. We make a note of the residual sum of squares.
 = 156.81 Model | 1230.2039 2 615.101949 Prob > F = 0.0000 Residual | 2224.04347 567 3.92247526 R-squared = 0.3561 ---------+------------------")
47
. reg S ASVABC SM SF Source | SS df MS Number of obs = F( 3, 566) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ASVABC | SM | SF | _cons | F TESTS OF GOODNESS OF FIT 62 If all the variables are correlated, it is possible for all of them to have low marginal explanatory power and for none of the t tests to be significant, even though the F test for their joint explanatory power is highly significant. If this is the case, the model is said to be suffering from the problem of multicollinearity
 = 110.83 Model | 1278.24153 3 426.080508 Prob > F = 0.0000 Residual | 2176.00584 566 3.84453329 R-squared = 0.3700 ---------+--------------")
48
пример теста на линейные ограничения reg lnQ lnL lnK Source | SS df MS Number of obs = F( 2, 12) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = lnQ | Coef. Std. Err. t P>|t| [95% Conf. Interval] lnL | lnK | _cons | test _b[lnK]+_b[lnL]=1 ( 1) _b[lnK]+_b[lnL]=1 F( 1, 12) = 0.01 Prob > F =
 = 186.81 Model |.061682789 2.030841395 Prob > F = 0.0000 Residual |.001981101 12.000165092 R-squared = 0.")
49
КОРОТКАЯ ИЛИ ДЛИННАЯ РЕГРЕССИЯ

51
. reg S ASVABC SM SF Source | SS df MS Number of obs = F( 3, 566) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ASVABC | SM | SF | _cons | F TESTS OF GOODNESS OF FIT 35 Регрессор SM исключать не следует
 = 110.83 Model | 1278.24153 3 426.080508 Prob > F = 0.0000 Residual | 2176.00584 566 3.84453329 R-squared = 0.3700 ---------+--------------")
57
ПРОПУСК СУЩЕСТВЕННЫХ ПЕРЕМЕННЫХ

61
VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE Y X3X3 X2X2 direct effect of X 2, holding X 3 constant effect of X 3 apparent effect of X 2, acting as a mimic for X The intuitive reason is that, in addition to its direct effect b2, X2 has an apparent indirect effect as a consequence of acting as a proxy for the missing X3. The strength of the proxy effect depends on two factors: the strength of the effect of X 3 on Y, which is given by 3, and the ability of X 2 to mimic X 3.

62
11 VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE Y X3X3 X2X2 direct effect of X 2, holding X 3 constant effect of X 3 apparent effect of X 2, acting as a mimic for X The ability of X 2 to mimic X 3 is determined by the slope coefficient obtained when X 3 is regressed on X 2, which of course is Cov(X 2, X 3 )/Var(X 2 ).

63
VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE 12 We will now derive the expression for the bias mathematically. Since we are mistakenly fitting a simple regression model, the slope coefficient is calculated as Cov(X 2, Y)/Var(X 2 ). The first step is to substitute for Y from the true model..
/Var(X 2 ). Th")
64
VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE 13 We use Covariance Rule 1 to decompose the numerator.

65
VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE 14 The first term is 0 because 1 is a constant. 2 and 3 can be taken out of the second and third terms.

66
15 Hence we have demonstrated that b 2 has three components. VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE

68
16 To investigate biasedness or unbiasedness, we take the expected value of b 2.

69
VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE 17 Using Expected Value Rule 1, we can decompose the expected value as the sum of the expected values of the components.

70
18 The first two components are fixed since 2 and 3 are constants and X 2 and X 3 are nonstochastic, by assumption. The expected value of the third term is 0. (For a proof, see the second sequence in Chapter 3.) VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE
 VARIABLE MISSPECIFICATION I: OMISSION")
71
11 VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE Y X3X3 X2X2 direct effect of X 2, holding X 3 constant effect of X 3 apparent effect of X 2, acting as a mimic for X The ability of X 2 to mimic X 3 is determined by the slope coefficient obtained when X 3 is regressed on X 2, which of course is Cov(X 2, X 3 )/Var(X 2 ).

73
. reg S ASVABC SM Source | SS df MS Number of obs = F( 2, 567) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ASVABC | SM | _cons | We will illustrate the bias using an educational attainment model. To keep the analysis simple, we will assume that S depends on ASVABC and SM. The output above shows the corresponding regression using EAEF Data Set 21. VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE
 = 156.81 Model | 1230.2039 2 615.101949 Prob > F = 0.0000 Residual | 2224.04347 567 3.92247526 R-squared = 0.3561 ---------+------------------")
74
21 We will run the regression a second time, omitting SM. Before we do this, we will try to predict the direction of the bias in the coefficient of ASVABC. VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE. reg S ASVABC SM Source | SS df MS Number of obs = F( 2, 567) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ASVABC | SM | _cons |

76
22 It is reasonable to suppose, as a matter of common sense, that 3 is positive. This assumption is strongly supported by the fact that its estimate in the multiple regression is positive and highly significant. VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE. reg S ASVABC SM Source | SS df MS Number of obs = F( 2, 567) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ASVABC | SM | _cons |

77
23 The correlation between ASVABC and SM is positive, so their covariance must be positive. Var(ASVABC) is automatically positive. Hence the bias should be positive. VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE. reg S ASVABC SM Source | SS df MS Number of obs = F( 2, 567) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ASVABC | SM | _cons | cor SM ASVABC (obs=570) | SM ASVABC SM| ASVABC|
 is automatically positive. Hence the bias should be positive. VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE. reg S ASVABC SM Source")
78
. reg S ASVABC Source | SS df MS Number of obs = F( 1, 568) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ASVABC | _cons | Here is the regression omitting SM. VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE
 = 284.89 Model | 1153.80864 1 1153.80864 Prob > F = 0.0000 Residual | 2300.43873 568 4.05006818 R-squared = 0.3340 ---------+--------------------")
79
. reg S ASVABC SM S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ASVABC | SM | _cons | reg S ASVABC S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ASVABC | _cons | As you can see, the coefficient of ASVABC is indeed higher when SM is omitted. Part of the difference may be due to pure chance, but part is attributable to the bias. VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE
![. reg S ASVABC SM ------------------------------------------------------------------------------ S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ---------+-------------------------------------------------------------------- ASVABC |.1381062.0097494](http://images.myshared.ru/17/1065189/slide_79.jpg ". reg S ASVABC SM ------------------------------------------------------------------------------ S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ---------+-------------------------------------------------------------------- ASVABC |.1381062.0097494")
80
. reg S SM Source | SS df MS Number of obs = F( 1, 568) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = S | Coef. Std. Err. t P>|t| [95% Conf. Interval] SM | _cons | Here is the regression omitting ASVABC instead of SM. We would expect b 3 to be upwards biased. We anticipate that 2 is positive and we know that both the covariance and variance terms in the bias expression are positive. VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE
 = 83.59 Model | 443.110436 1 443.110436 Prob > F = 0.0000 Residual | 3011.13693 568 5.30129742 R-squared = 0.1283 ---------+-------------------------")
81
. reg S ASVABC SM S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ASVABC | SM | _cons | reg S SM S | Coef. Std. Err. t P>|t| [95% Conf. Interval] SM | _cons | corr ASVABC SM,cov (obs=570) | ASVABC SM ASVABC | SM | In this case the bias is quite dramatic. The coefficient of SM has more than doubled. (The reason for the bigger effect is that Var(SM) is much smaller than Var(ASVABC), while 2 and 3 are similar in size, judging by their estimates.) VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE
![. reg S ASVABC SM ------------------------------------------------------------------------------ S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ---------+-------------------------------------------------------------------- ASVABC |.1381062.0097494](http://images.myshared.ru/17/1065189/slide_81.jpg ". reg S ASVABC SM ------------------------------------------------------------------------------ S | Coef. Std. Err. t P>|t| [95% Conf. Interval] ---------+-------------------------------------------------------------------- ASVABC |.1381062.0097494")
82
. reg S ASVABC SM Source | SS df MS Number of obs = F( 2, 567) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = reg S ASVABC Source | SS df MS Number of obs = F( 1, 568) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = reg S SM Source | SS df MS Number of obs = F( 1, 568) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = Finally, we will investigate how R 2 behaves when a variable is omitted. In the simple regression of S on ASVABC, R 2 is 0.33, and in the simple regression of S on SM it is VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE
 = 156.81 Model | 1230.2039 2 615.101949 Prob > F = 0.0000 Residual | 2224.04347 567 3.92247526 R-squared = 0.3561 ---------+------------------")
83
. reg S ASVABC SM Source | SS df MS Number of obs = F( 2, 567) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = reg S ASVABC Source | SS df MS Number of obs = F( 1, 568) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = reg S SM Source | SS df MS Number of obs = F( 1, 568) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE 29 Does this imply that ASVABC explains 33% of the variance in S and SM 13%? No, because the multiple regression reveals that their joint explanatory power is 0.36, not 0.46.
 = 156.81 Model | 1230.2039 2 615.101949 Prob > F = 0.0000 Residual | 2224.04347 567 3.92247526 R-squared = 0.3561 ---------+------------------")
84
. reg S ASVABC SM Source | SS df MS Number of obs = F( 2, 567) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = reg S ASVABC Source | SS df MS Number of obs = F( 1, 568) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = reg S SM Source | SS df MS Number of obs = F( 1, 568) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE 30 In the second regression, ASVABC is partly acting as a proxy for SM, and this inflates its apparent explanatory power. Similarly, in the third regression, SM is partly acting as a proxy for ASVABC, again inflating its apparent explanatory power.
 = 156.81 Model | 1230.2039 2 615.101949 Prob > F = 0.0000 Residual | 2224.04347 567 3.92247526 R-squared = 0.3561 ---------+------------------")
86
. reg LGEARN S MALE Source | SS df MS Number of obs = F( 2, 567) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = LGEARN | Coef. Std. Err. t P>|t| [95% Conf. Interval] S | MALE | _cons | However, it is also possible for omitted variable bias to lead to a reduction in the apparent explanatory power of a variable. This will be demonstrated using a simple earnings function model, supposing the logarithm of earnings to depend on S and MALE. VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE
 = 65.74 Model | 28.951332 2 14.475666 Prob > F = 0.0000 Residual | 124.850561 567.220194992 R-squared = 0.1882 ---------+-------------------")
87
. reg LGEARN S MALE Source | SS df MS Number of obs = F( 2, 567) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = LGEARN | Coef. Std. Err. t P>|t| [95% Conf. Interval] S | MALE | _cons | VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE 32 If we omit MALE from the regression, the coefficient of S should be subject to a downward bias. 3 is likely to be positive, and we know that Var(S) is positive, but Cov(S, MALE) is negative because S and MALE are negatively correlated.. cor S MALE (obs=570) | S MALE S| MALE|
 = 65.74 Model | 28.951332 2 14.475666 Prob > F = 0.0000 Residual | 124.850561 567.220194992 R-squared = 0.1882 ---------+-------------------")
88
. reg LGEARN S MALE Source | SS df MS Number of obs = F( 2, 567) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = LGEARN | Coef. Std. Err. t P>|t| [95% Conf. Interval] S | MALE | _cons | For the same reasons, the coefficient of MALE in a simple regression of LGEARN on MALE should be downwards biased. VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE. cor S MALE (obs=570) | S MALE S| MALE|
 = 65.74 Model | 28.951332 2 14.475666 Prob > F = 0.0000 Residual | 124.850561 567.220194992 R-squared = 0.1882 ---------+-------------------")
89
. reg LGEARN S MALE LGEARN | Coef. Std. Err. t P>|t| [95% Conf. Interval] S | MALE | _cons | reg LGEARN S LGEARN | Coef. Std. Err. t P>|t| [95% Conf. Interval] S | _cons | reg LGEARN MALE LGEARN | Coef. Std. Err. t P>|t| [95% Conf. Interval] MALE | _cons | As can be seen, the coefficients of S and MALE are indeed lower in the simple regressions. VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE
![. reg LGEARN S MALE ------------------------------------------------------------------------------ LGEARN | Coef. Std. Err. t P>|t| [95% Conf. Interval] ---------+-------------------------------------------------------------------- S |.0818944.007997](http://images.myshared.ru/17/1065189/slide_89.jpg ". reg LGEARN S MALE ------------------------------------------------------------------------------ LGEARN | Coef. Std. Err. t P>|t| [95% Conf. Interval] ---------+-------------------------------------------------------------------- S |.0818944.007997")
90
. reg LGEARN S MALE Source | SS df MS Number of obs = F( 2, 567) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = reg LGEARN S Source | SS df MS Number of obs = F( 1, 568) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = reg LGEARN MALE Source | SS df MS Number of obs = F( 1, 568) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = A comparison of R 2 for the three regressions shows that the sum of R 2 in the simple regressions is actually less than R 2 in the multiple regression. However, in this case the difference is small because the negative correlation between S and MALE is small (-0.05) VARIABLE MISSPECIFICATION I: OMISSION OF A RELEVANT VARIABLE
 = 65.74 Model | 28.951332 2 14.475666 Prob > F = 0.0000 Residual | 124.850561 567.220194992 R-squared = 0.1882 ---------+-------------------")
93
ВКЛЮЧЕНИЕ НЕСУЩЕСТВЕННЫХ ПЕРМЕННЫХ

97
. reg LGEARN S ASVABC Source | SS df MS Number of obs = F( 2, 567) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = LGEARN | Coef. Std. Err. t P>|t| [95% Conf. Interval] S | ASVABC | _cons | The analysis will be illustrated using a basic semi-logarithmic earnings function. The result of regressing LGEARN on S and ASVABC is shown above. VARIABLE MISSPECIFICATION II: INCLUSION OF AN IRRELEVANT VARIABLE
 = 57.45 Model | 25.9166749 2 12.9583374 Prob > F = 0.0000 Residual | 127.885218 567.225547121 R-squared = 0.1685 ---------+---------------")
98
. reg LGEARN S ASVABC SM SF Source | SS df MS Number of obs = F( 4, 565) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = LGEARN | Coef. Std. Err. t P>|t| [95% Conf. Interval] S | ASVABC | SM | SF | _cons | Now add the parental education variables, SM and SF. These variables are determinants of educational attainment, and hence indirectly affect earnings, but there is no evidence that they have any additional direct effect on earnings. The fact that the t statistics of both variables are low is evidence that they are probably irrelevant VARIABLE MISSPECIFICATION II: INCLUSION OF AN IRRELEVANT VARIABLE
 = 29.22 Model | 26.3617806 4 6.59044515 Prob > F = 0.0000 Residual | 127.440112 565.22555772 R-squared = 0.1714 ---------+----------")
99
. reg LGEARN S ASVABC LGEARN | Coef. Std. Err. t P>|t| [95% Conf. Interval] S | ASVABC | _cons | reg LGEARN S ASVABC SM SF LGEARN | Coef. Std. Err. t P>|t| [95% Conf. Interval] S | ASVABC | SM | SF | _cons | There is no evidence that the inclusion of the parental education variables has caused the other coefficients to be biased. The other coefficients have changed, but the changes are small in relation to the standard errors and appear to be chance movements. VARIABLE MISSPECIFICATION II: INCLUSION OF AN IRRELEVANT VARIABLE
![. reg LGEARN S ASVABC ------------------------------------------------------------------------------ LGEARN | Coef. Std. Err. t P>|t| [95% Conf. Interval] ---------+-------------------------------------------------------------------- S |.0544266.0099](http://images.myshared.ru/17/1065189/slide_99.jpg ". reg LGEARN S ASVABC ------------------------------------------------------------------------------ LGEARN | Coef. Std. Err. t P>|t| [95% Conf. Interval] ---------+-------------------------------------------------------------------- S |.0544266.0099")
100
. reg LGEARN S ASVABC LGEARN | Coef. Std. Err. t P>|t| [95% Conf. Interval] S | ASVABC | _cons | reg LGEARN S ASVABC SM SF LGEARN | Coef. Std. Err. t P>|t| [95% Conf. Interval] S | ASVABC | SM | SF | _cons | VARIABLE MISSPECIFICATION II: INCLUSION OF AN IRRELEVANT VARIABLE 14 The standard errors are larger in the misspecified model, reflecting the loss of efficiency.
![. reg LGEARN S ASVABC ------------------------------------------------------------------------------ LGEARN | Coef. Std. Err. t P>|t| [95% Conf. Interval] ---------+-------------------------------------------------------------------- S |.0544266.0099](http://images.myshared.ru/17/1065189/slide_100.jpg ". reg LGEARN S ASVABC ------------------------------------------------------------------------------ LGEARN | Coef. Std. Err. t P>|t| [95% Conf. Interval] ---------+-------------------------------------------------------------------- S |.0544266.0099")
101
. reg LGEARN S ASVABC LGEARN | Coef. Std. Err. t P>|t| [95% Conf. Interval] S | ASVABC | _cons | reg LGEARN S ASVABC SM SF LGEARN | Coef. Std. Err. t P>|t| [95% Conf. Interval] S | ASVABC | SM | SF | _cons | VARIABLE MISSPECIFICATION II: INCLUSION OF AN IRRELEVANT VARIABLE 15 However, the loss of efficiency is not very great. The parental education variables are correlated with both S and ASVABC but, with a sample as large as the present one, the correlation has to be greater for the loss of efficiency to become a serious problem.. cor S ASVABC SM SF (obs=570) | S ASVABC SM SF S| ASVABC| SM| SF| pcorr SM S ASVABC SF (obs=570) Partial correlation of SM with Variable Corr.Sig. S ASVABC SF pcorr SF S ASVABC SM (obs=570) Partial correlation of SFwith Variable Corr.Sig. S ASVABC SM
![. reg LGEARN S ASVABC ------------------------------------------------------------------------------ LGEARN | Coef. Std. Err. t P>|t| [95% Conf. Interval] ---------+-------------------------------------------------------------------- S |.0544266.0099](http://images.myshared.ru/17/1065189/slide_101.jpg ". reg LGEARN S ASVABC ------------------------------------------------------------------------------ LGEARN | Coef. Std. Err. t P>|t| [95% Conf. Interval] ---------+-------------------------------------------------------------------- S |.0544266.0099")
102
Consequences of Variable Misspecification True Model Fitted Model Correct specification, no problems Correct specification, no problems Coefficients are biased (in general). Standard errors are invalid. VARIABLE MISSPECIFICATION II: INCLUSION OF AN IRRELEVANT VARIABLE The effects are different from those of omitted variable misspecification. In this case the coefficients in general remain unbiased, but they are inefficient. The standard errors remain valid, but are needlessly large. 2 Coefficients are unbiased (in general), but inefficient. Standard errors are valid (in general)
. Standard errors are invalid. VARIABLE MISSPECIFICATION II: INCLUSION OF AN I")
103
COST = -55, ,000TECH + 143,000WORKER + 53,000VOC + 343N General SchoolCOST= -55, N (TECH = WORKER = VOC = 0) Technical SchoolCOST= -55, , N (TECH = 1; WORKER = VOC = 0) = 99, N Skilled Workers SchoolCOST= -55, , N (WORKER = 1; TECH = VOC = 0) = 88, N Vocational SchoolCOST= -55, , N (VOC = 1; TECH = WORKER = 0) = -2, N DUMMY CLASSIFICATION WITH MORE THAN TWO CATEGORIES Note that in each case the annual marginal cost per student is estimated at 343 yuan. The model specification assumes that this figure does not differ according to type of school. ^ ^ ^ ^ ^ 29
 Technical SchoolCOST= -55,000 + 154,000 + 343N (TECH = 1; WORKER = VOC = 0) = 99,000 + 343N Skilled Workers SchoolCOST= -55,0")
104
DUMMY CLASSIFICATION WITH MORE THAN TWO CATEGORIES The four cost functions are illustrated graphically. 30

105
. reg COST N TECH WORKER VOC Source | SS df MS Number of obs = F( 4, 69) = Model | e e+11 Prob > F = Residual | e e+09 R-squared = Adj R-squared = Total | e e+10 Root MSE = COST | Coef. Std. Err. t P>|t| [95% Conf. Interval] N | TECH | WORKER | VOC | _cons | DUMMY CLASSIFICATION WITH MORE THAN TWO CATEGORIES We can perform t tests on the coefficients in the usual way. The t statistic for N is 8.52, so the marginal cost is (very) significantly different from 0, as we would expect. 31
 = 29.63 Model | 9.2996e+11 4 2.3249e+11 Prob > F = 0.0000 Residual | 5.4138e+11 69 7.8461e+09 R-squared = 0.6320 ---------+----------")
106
. reg COST N TECH WORKER VOC Source | SS df MS Number of obs = F( 4, 69) = Model | e e+11 Prob > F = Residual | e e+09 R-squared = Adj R-squared = Total | e e+10 Root MSE = COST | Coef. Std. Err. t P>|t| [95% Conf. Interval] N | TECH | WORKER | VOC | _cons | DUMMY CLASSIFICATION WITH MORE THAN TWO CATEGORIES Finally we will perform an F test of the joint explanatory power of the dummy variables as a group. The null hypothesis is H0: dT = dW = dV = 0. The alternative hypothesis is that at least one d is different from 0. The residual sum of squares in the specification including the dummy variables is 5.41×
 = 29.63 Model | 9.2996e+11 4 2.3249e+11 Prob > F = 0.0000 Residual | 5.4138e+11 69 7.8461e+09 R-squared = 0.6320 ---------+----------")
107
. reg COST N Source | SS df MS Number of obs = F( 1, 72) = Model | e e+11 Prob > F = Residual | e e+10 R-squared = Adj R-squared = Total | e e+10 Root MSE = 1.1e+05. reg COST N TECH WORKER VOC Source | SS df MS Number of obs = F( 4, 69) = Model | e e+11 Prob > F = Residual | e e+09 R-squared = Adj R-squared = Total | e e+10 Root MSE = Thus we reject H 0 at a high significance level. This is not exactly surprising since t tests show that TECH and WORKER have highly significant coefficients. DUMMY CLASSIFICATION WITH MORE THAN TWO CATEGORIES 45
 = 46.82 Model | 5.7974e+11 1 5.7974e+11 Prob > F = 0.0000 Residual | 8.9160e+11 72 1.2383e+10 R-squared = 0.3940 ---------+--------------------------")
108
. reg COST N OCC NOCC Source | SS df MS Number of obs = F( 3, 70) = Model | e e+11 Prob > F = Residual | e e+09 R-squared = Adj R-squared = Total | e e+10 Root MSE = COST | Coef. Std. Err. t P>|t| [95% Conf. Interval] N | OCC | NOCC | _cons | SLOPE DUMMY VARIABLES Weird or not, the procedure works very well. Here is the regression output using the full sample of 74 schools. We will begin by interpreting the regression coefficients. 12
 = 49.64 Model | 1.0009e+12 3 3.3363e+11 Prob > F = 0.0000 Residual | 4.7045e+11 70 6.7207e+09 R-squared = 0.6803 ---------+-----------------")
109
SLOPE DUMMY VARIABLES Putting OCC equal to 1, and hence NOCC equal to N, we estimate that the annual overhead costs of the occupational schools are 47,000 yuan and the annual marginal cost per student is 436 yuan. 15 COST = 51, ,000 OCC + 152N + 284NOCC Regular schoolCOST= 51, N (OCC = NOCC = 0) Occupational schoolCOST= 51, , N + 284N (OCC = 1; NOCC = N) = 47, N ^ ^ ^

110
SLOPE DUMMY VARIABLES You can see that the cost functions fit the data much better than before and that the real difference is in the marginal cost, not the overhead cost. 16

111
SLOPE DUMMY VARIABLES Now we can see why we had a nonsensical negative estimate of the overhead cost of a regular school in previous specifications. The assumption of the same marginal cost led to an estimate of the marginal cost that was a compromise between the marginal costs of occupational and regular schools. 17

112
SLOPE DUMMY VARIABLES The cost function for regular schools was too steep and as a consequence the intercept was underestimated, actually becoming negative and indicating that something must be wrong with the specification of the model. 19

113
SLOPE DUMMY VARIABLES We can perform t tests as usual. The t statistic for the coefficient of NOCC is 3.76, so the marginal cost per student in an occupational school is significantly higher than that in a regular school. 20. reg COST N OCC NOCC Source | SS df MS Number of obs = F( 3, 70) = Model | e e+11 Prob > F = Residual | e e+09 R-squared = Adj R-squared = Total | e e+10 Root MSE = COST | Coef. Std. Err. t P>|t| [95% Conf. Interval] N | OCC | NOCC | _cons |

114
SLOPE DUMMY VARIABLES The coefficient of OCC is now negative, suggesting that the overhead costs of occupational schools are actually lower than those of regular schools. This is unlikely. However, the t statistic is only -0.09, so we do not reject the null hypothesis that the overhead costs of the two types of school are the same. 21. reg COST N OCC NOCC Source | SS df MS Number of obs = F( 3, 70) = Model | e e+11 Prob > F = Residual | e e+09 R-squared = Adj R-squared = Total | e e+10 Root MSE = COST | Coef. Std. Err. t P>|t| [95% Conf. Interval] N | OCC | NOCC | _cons |

115
SLOPE DUMMY VARIABLES We can also perform an F test of the joint explanatory power of the dummy variables, comparing RSS when the dummy variables are included with RSS when they are not. The null hypothesis is that the coefficients of OCC and NOCC are both equal to 0. The alternative hypothesis is that one or both are nonzero. 23. reg COST N OCC NOCC Source | SS df MS Number of obs = F( 3, 70) = Model | e e+11 Prob > F = Residual | e e+09 R-squared = Adj R-squared = Total | e e+10 Root MSE = reg COST N Source | SS df MS Number of obs = F( 1, 72) = Model | e e+11 Prob > F = Residual | e e+10 R-squared = Adj R-squared = Total | e e+10 Root MSE = 1.1e+05

116
SLOPE DUMMY VARIABLES. reg COST N OCC NOCC Source | SS df MS Number of obs = F( 3, 70) = Model | e e+11 Prob > F = Residual | e e+09 R-squared = Adj R-squared = Total | e e+10 Root MSE = reg COST N Source | SS df MS Number of obs = F( 1, 72) = Model | e e+11 Prob > F = Residual | e e+10 R-squared = Adj R-squared = Total | e e+10 Root MSE = 1.1e+05 Thus we conclude that at least one of the dummy variable coefficients is different from 0. We knew this already from the t tests, so in this case the F test does not actually add anything. 29
 = 49.64 Model | 1.0009e+12 3 3.3363e+11 Prob > F = 0.0000 Residual | 4.7045e+11 70 6.7207e+09 R-squared = 0.6803 ------")
117
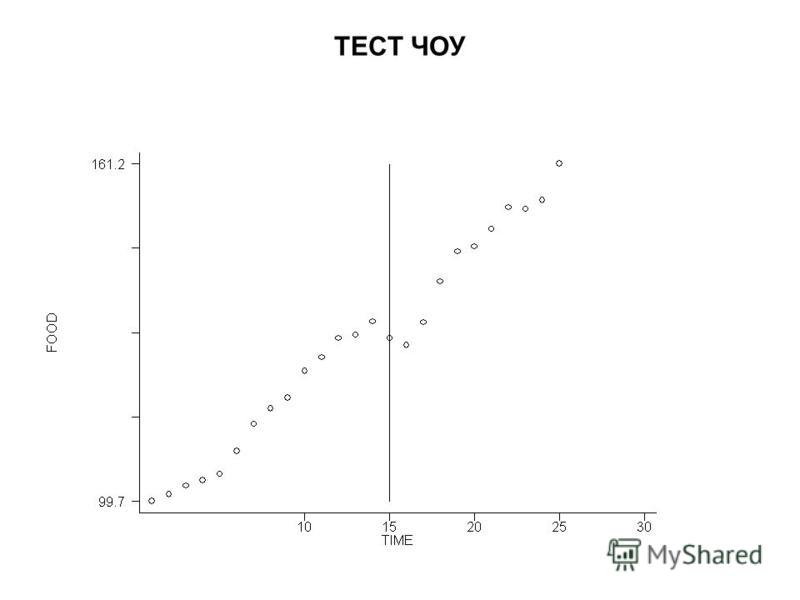
ТЕСТ ЧОУ

119
. reg food time if (time>14) Source | SS df MS Number of obs = F( 1, 9) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = reg food time if (time<15) Source | SS df MS Number of obs = F( 1, 12) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = food | Coef. Std. Err. t P>|t| time | _cons | food | Coef. Std. Err. t P>|t|] time | _cons | reg food time Source | SS df MS Number of obs = F( 1, 23) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = food | Coef. Std. Err. t P>|t| | ime | _cons |
 Source | SS df MS Number of obs = 11 --------------+------------------------------ F( 1, 9) = 185.03 Model | 1166.42953 1 1166.42953 Prob > F = 0.0000 Residual | 56.7358694 9 6.30398549 R-squared = 0.9536 -------------+--")
120
ТЕСТ ЧОУ

121
. g d=(time>14). g dtime=d*time. reg food time dtime d Source | SS df MS Number of obs = F( 3, 21) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = food | Coef. Std. Err. t P>|t| [95% Conf. Interval] time | dtime | d | _cons | reg food time Source | SS df MS Number of obs = F( 1, 23) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = food | Coef. Std. Err. t P>|t| [95% Conf. Interval] time | _cons |
. g dtime=d*time. reg food time dtime d Source | SS df MS Number of obs = 25 -------------+------------------------------ F( 3, 21) = 631.94 Model | 8386.95225 3 2795.65075 Prob > F = 0.0000 Residual | 92.9016073 21 4.42388606 R-square")
122
ТЕСТ ЧОУ. test _b[d]=0 ( 1) d = 0.0 F( 1, 21) = Prob > F = test _b[dtime]=0,accumulate ( 1) d = 0.0 ( 2) dtime = 0.0 F( 2, 21) = Prob > F =
![ТЕСТ ЧОУ. test _b[d]=0 ( 1) d = 0.0 F( 1, 21) = 11.67 Prob > F = 0.0026. test _b[dtime]=0,accumulate ( 1) d = 0.0 ( 2) dtime = 0.0 F( 2, 21) = 10.81 Prob > F = 0.0006](http://images.myshared.ru/17/1065189/slide_122.jpg "ТЕСТ ЧОУ. test _b[d]=0 ( 1) d = 0.0 F( 1, 21) = 11.67 Prob > F = 0.0026. test _b[dtime]=0,accumulate ( 1) d = 0.0 ( 2) dtime = 0.0 F( 2, 21) = 10.81 Prob > F = 0.0006")
123
CHOW TEST 5 We will illustrate it using the data for the 74 secondary schools in Shanghai. The scatter diagram plots the data on annual recurrent expenditure and number of students. This is the scatter diagram with the regression line.

124
. reg COST N Source | SS df MS Number of obs = F( 1, 72) = Model | e e+11 Prob > F = Residual | e e+10 R-squared = Adj R-squared = Total | e e+10 Root MSE = 1.1e COST | Coef. Std. Err. t P>|t| [95% Conf. Interval] N | _cons | CHOW TEST 4 Here is the regression output when COST is regressed on N, making no distinction between the different types of school.
 = 46.82 Model | 5.7974e+11 1 5.7974e+11 Prob > F = 0.0000 Residual | 8.9160e+11 72 1.2383e+10 R-squared = 0.3940 ---------+--------------------------")
125
CHOW TEST 6 Now we make a distinction between occupational schools and regular schools and run separate regressions for the two subsamples.

126
. reg COST N if OCC==1 Source | SS df MS Number of obs = F( 1, 32) = Model | e e+11 Prob > F = Residual | e e+10 R-squared = Adj R-squared = Total | e e+10 Root MSE = 1.0e COST | Coef. Std. Err. t P>|t| [95% Conf. Interval] N | _cons | CHOW TEST 7 This is the regression output when COST is regressed on N using the subsample of 34 occupational schools.
 = 55.52 Model | 6.0538e+11 1 6.0538e+11 Prob > F = 0.0000 Residual | 3.4895e+11 32 1.0905e+10 R-squared = 0.6344 ---------+----------------")
127
. reg COST N if OCC==0 Source | SS df MS Number of obs = F( 1, 38) = Model | e e+10 Prob > F = Residual | e e+09 R-squared = Adj R-squared = Total | e e+09 Root MSE = COST | Coef. Std. Err. t P>|t| [95% Conf. Interval] N | _cons | CHOW TEST 8 And this is the regression output when COST is regressed on N for the subsample of 40 regular schools.
 = 13.53 Model | 4.3273e+10 1 4.3273e+10 Prob > F = 0.0007 Residual | 1.2150e+11 38 3.1973e+09 R-squared = 0.2626 ---------+----------------")
128
CHOW TEST 10 The regression line for the pooled sample (entire sample, making no distinction) is shown for comparison.
 is shown for comparison.")
129
CHOW TEST 11 The diagram shows the residuals in the regression using only the occupational schools.

130
CHOW TEST 12 Now the corresponding residuals for the regression using the pooled sample are shown.

131
CHOW TEST 13 RSS = 3.49 x RSS = 5.55 x The two sets of residuals are isolated for comparison. RSS is smaller for the residuals from the subsample regression. This must be the case. Why? (Try to answer before continuing.)
")
132
CHOW TEST 17 Next we turn to the regular schools. Here are the residuals for the subsample regression.

133
CHOW TEST 18 And now those for the same observations in the pooled regression.

134
RSS = 12.2 x RSS = 33.6 x The two sets of residuals are shown for comparison. Again, RSS must be higher for the pooled sample regression. CHOW TEST 19

135
RESIDUAL SUM OF SQUARES (x10 11 ) RegressionOccupationalRegularTotal RSS 1 RSS 2 (RSS 1 +RSS 2 ) Separate RSS P Pooled CHOW TEST 20 The table summarizes the RSS data for the two types of school in the separate and pooled regressions.
 RegressionOccupationalRegularTotal RSS 1 RSS 2 (RSS 1 +RSS 2 ) Separate3.491.224.71 RSS P Pooled5.553.368.91 CHOW TEST 20 The table summarizes the RSS data for the two types of school in the separate and pooled regre")
136
CHOW TEST 24 This is obtained directly from the original pooled regression. There is no need to calculate the occupational and regular components - we are interested only in the total.

137
CHOW TEST 25 We are interested in seeing whether there is a significant reduction in the total when we run separate regressions for the two subsamples. RESIDUAL SUM OF SQUARES (x10 11 ) RegressionOccupationalRegularTotal RSS 1 RSS 2 (RSS 1 +RSS 2 ) Separate RSS P Pooled
 RegressionOccupationalRegularTotal RSS 1 RSS 2 (RSS 1 +RSS 2 ) S")
138
CHOW TEST F(k, n – 2k) = overall reduction in RSS when separate regressions are run cost in degrees of freedom total RSS remaining when separate regressions are run degrees of freedom remaining 38 The reduction in the residual sum of squares is therefore significant at the 0.1% level. We conclude that the pooled cost function is an inadequate specification and that we should run separate regressions for the two types of school.
 = overall reduction in RSS when separate regressions are run cost in degrees of freedom total RSS remaining when separate regressions are run degrees of freedom remaining 38 The reduction in the residual sum of squares is there")
139
CHOW TEST AND DUMMY VARIABLE GROUP TEST 5 The regression line is shown graphically.

140
CHOW TEST AND DUMMY VARIABLE GROUP TEST 9 Here are the regression lines for the two subsamples.

141
Whole sample COST = 24, NRSS = 8.91x10 11 Whole sample COST = 51, ,000OCC + 152N + 284NOCCRSS = 4.71x10 11 CHOW TEST AND DUMMY VARIABLE GROUP TEST 13 ^ ^ The critical value of F at the 0.1% level with 2 and 60 degrees of freedom is 7.8. The critical value of F(2,70) must be lower. Hence we conclude that the dummy variables do have significant explanatory power and the cost functions are different.

142
Regular schools only COST = 51, NRSS = 1.22x10 11 Occupational schools only COST = 47, NRSS = 3.49x10 11 Whole sample, with dummy variables COST = 51, ,000OCC + 152N + 284NOCCRSS = 4.71x10 11 Implicit cost function for regular schools COST = 51, N Implicit cost function for occupational schools COST = 47, N CHOW TEST AND DUMMY VARIABLE GROUP TEST 24 ^ ^ ^ ^ ^ Since the cost functions implicit in the dummy variable regression coincide with those in the separate regressions, the residuals will be the same. It follows that RSS for the dummy variable regression must be equal the sum of RSS for the separate regressions.

143
Regular schools only COST = 51, NRSS = 1.22x10 11 Occupational schools only COST = 47, NRSS = 3.49x10 11 Whole sample, with dummy variables COST = 51, ,000OCC + 152N + 284NOCCRSS = 4.71x10 11 CHOW TEST AND DUMMY VARIABLE GROUP TEST 34 ^ ^ ^ However, it is more informative because you can perform t tests on the individual dummy coefficients and find out where the functions differ, if they do.

145
ТЕСТЫ НА ФУНКЦИОНАЛЬНУЮ ФОРМУ 1.RESET тест Рамсея 2.J-тест Дэвидсона и МакКиннона 3.PE-тест МакКинона 4.Метод Зарембки 5.Тест Кокса-Бокса 6.PC-тест Амемии (Акаике) 7.Информационный критерий Шварца 8.Информационный критерий Акаике
 7.Информационный критерий Шварца 8.Информационный критерий Акаике")
146
RESET тест Рамсея Regression Equation Specification Erorr Test

147
RESET тест Рамсея Regression Equation Specification Erorr Test. reg EARNINGS MALE ASVABC AGE S Source | SS df MS Number of obs = F( 4, 565) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = EARNINGS | Coef. Std. Err. t P>|t| [95% Conf. Interval] MALE | ASVABC | AGE | S | _cons | ovtest Ramsey RESET test using powers of the fitted values of EARNINGS Ho: model has no omitted variables F(3, 562) = 3.26 Prob > F = ovtest,rhs Ramsey RESET test using powers of the independent variables Ho: model has no omitted variables F(9, 556) = 2.50 Prob > F =
 = 26.01 Model | 5971.29146 4 1492.82286 Prob > F = 0.0000 Res")
148
ПРОЦЕДУРЫ ПОШАГОВОГО ОТБОРА 1.ПОСЛЕДОВАТЕЛЬНОГО ПРИСОЕДИНЕНИЯ 2.ПОСЛЕДОВАТЕЛЬНОГО УДАЛЕНИЯ 3.ПРИСОЕДИНЕНИЯ-УДАЛЕНИЯ 4.УДАЛЕНИЯ-ПРИСОЕДИНЕНИЯ См.: Магнус, Катышев, Пересецкий «Эконометрика. Начальный курс» Айвазян, Мхитарян «Прикладная статистика и эконометрика»

149
ПРОЦЕДУРЫ ПОШАГОВОГО ОТБОРА. sw reg EARNINGS MALE ETHWHITE COLLBARG URBAN ASVABC AGE S, pr(.15) begin with full model p = >= removing ETHWHITE p = >= removing AGE Source | SS df MS Number of obs = F( 5, 564) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = EARNINGS | Coef. Std. Err. t P>|t| [95% Conf. Interval] MALE | S | COLLBARG | URBAN | ASVABC | _cons |
 begin with full model p = 0.3153 >= 0.1500 removing ETHWHITE p = 0.2332 >= 0.1500 removing AGE Source | SS df MS Number of obs = 570 -------------+-------")
151
J-тест Дэвидсона-МакКиннона с равнение невложенных моделей

156
PE-тест МакКиннона сравнение невложенных моделей

159
. reg EARNINGS S EARNINGS | Coef. Std. Err. t P>|t| [95% Conf. Interval] S | _cons | predict EARN_hat. g lg_EARN_hat=log( EARN_hat). g lgEarn=log( EARNINGS). reg lgEarn S lgEarn | Coef. Std. Err. t P>|t| [95% Conf. Interval] S | _cons | predict lgEARN_hat. g EARN_exp_log=exp( lgEARN_hat). g dEARN= EARN_hat- EARN_exp_log. g dLgEARN= lg_EARN_hat- lgEARN_hat
![. reg EARNINGS S ------------------------------------------------------------------------------ EARNINGS | Coef. Std. Err. t P>|t| [95% Conf. Interval] ----------- --+---------------------------------------------------------------- S | 1.073055.13245](http://images.myshared.ru/17/1065189/slide_159.jpg ". reg EARNINGS S ------------------------------------------------------------------------------ EARNINGS | Coef. Std. Err. t P>|t| [95% Conf. Interval] ----------- --+---------------------------------------------------------------- S | 1.073055.13245")
160
PE-тест МакКиннона сравнение невложенных моделей. reg EARNINGS S dLgEARN EARNINGS | Coef. Std. Err. t P>|t| [95% Conf. Interval] S | dLgEARN | _cons | reg lgEarn S dEARN lgEarn | Coef. Std. Err. t P>|t| [95% Conf. Interval] S | dEARN | _cons |
![PE-тест МакКиннона сравнение невложенных моделей. reg EARNINGS S dLgEARN ------------------------------------------------------------------------------ EARNINGS | Coef. Std. Err. t P>|t| [95% Conf. Interval] ---------------+--------------------------](http://images.myshared.ru/17/1065189/slide_160.jpg "PE-тест МакКиннона сравнение невложенных моделей. reg EARNINGS S dLgEARN ------------------------------------------------------------------------------ EARNINGS | Coef. Std. Err. t P>|t| [95% Conf. Interval] ---------------+--------------------------")
165
8 BOX-COX TESTS The residual sums of squares are now directly comparable. The test statistic is as shown. It is distributed as a 2 (chi-squared) statistic under the null hypothesis that there is no difference in the fit.
 statistic under the null hypothesis that there is no difference in the fit.")
166
9 BOX-COX TESTS We will use the test to compare the fits of the linear and semi-logarithmic versions of a simple earnings function, using EAEF Data Set 21.

167
16 BOX-COX TESTS. means EARNINGS Variable | Type Obs Mean [95% Conf. Interval] EARNINGS | Arithmetic | Geometric | Harmonic g EARNSTAR= EARNINGS/ g LGEARNSTAR=log( EARNSTAR)
![16 BOX-COX TESTS. means EARNINGS Variable | Type Obs Mean [95% Conf. Interval] -------------+-------------------------------------------------------- EARNINGS | Arithmetic 570 13.11782 12.44201 13.79364 | Geometric 570 11.36039 10.88473 11.85684 | Ha](http://images.myshared.ru/17/1065189/slide_167.jpg "16 BOX-COX TESTS. means EARNINGS Variable | Type Obs Mean [95% Conf. Interval] -------------+-------------------------------------------------------- EARNINGS | Arithmetic 570 13.11782 12.44201 13.79364 | Geometric 570 11.36039 10.88473 11.85684 | Ha")
168
17 BOX-COX TESTS. reg EARNSTAR S Source | SS df MS Number of obs = F( 1, 568) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = EARNSTAR | Coef. Std. Err. t P>|t| [95% Conf. Interval] S | _cons | reg LGEARNSTAR S Source | SS df MS Number of obs = F( 1, 568) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = LGEARNSTAR | Coef. Std. Err. t P>|t| [95% Conf. Interval] S | _cons |
 = 65.64 Model | 30.818438 1 30.818438 Prob > F = 0.0000 Residual | 266.698183 568.469539054 R-squared = 0.1036 ------------")
169
19 BOX-COX TESTS The test statistic is This far exceeds the critical value of 2 with one degree of freedom, even at the 0.1% level, so we conclude that the semi-logarithmic version gives a significantly better fit.

172
9 BOX-COX TESTS. boxcox EARNSTAR AGE S SEX, model(theta) nolog Number of obs = 570 LR chi2(4) = Log likelihood = Prob > chi2 = EARNSTAR | Coef. Std. Err. z P>|z| [95% Conf. Interval] /lambda | /theta | Test Restricted H0: log likelihood chi2 Prob > chi theta=lambda = theta=lambda = theta=lambda = Estimates of scale-variant parameters | Coef Notrans | _cons | Trans AGE | S | /sigma |
 nolog Number of obs = 570 LR chi2(4) = 122.13 Log likelihood = -367.8914 Prob > chi2 = 0.000 ------------------------------------------------------------------------------ EARNSTAR | Coef. Std.")
173
9 BOX-COX TESTS. boxcox EARNSTAR AGE S SEX, model(rhsonly) nolog Estimating full model Number of obs = 570 LR chi2(4) = Log likelihood = Prob > chi2 = EARNSTAR | Coef. Std. Err. z P>|z| [95% Conf. Interval] /lambda | Test Restricted LR statistic P-Value H0: log likelihood chi2 Prob > chi lambda = lambda = lambda = Estimates of scale-variant parameters | Coef Notrans | _cons | Trans | AGE | S | SEX | /sigma |
 nolog Estimating full model Number of obs = 570 LR chi2(4) = 88.29 Log likelihood = -579.35478 Prob > chi2 = 0.000 ----------------------------------------------------------------------------")
174
9 BOX-COX TESTS. boxcox EARNSTAR AGE S SEX, model(lhsonly) nolog Number of obs = 570 LR chi2(3) = Log likelihood = Prob > chi2 = EARNSTAR | Coef. Std. Err. z P>|z| [95% Conf. Interval] /theta | Test Restricted LR statistic P-Value H0: log likelihood chi2 Prob > chi theta = theta = theta = Estimates of scale-variant parameters | Coef Notrans | AGE | S | SEX | _cons | /sigma |
 nolog Number of obs = 570 LR chi2(3) = 121.78 Log likelihood = -368.06337 Prob > chi2 = 0.000 ------------------------------------------------------------------------------ EARNSTAR | Coef. S")
175
9 BOX-COX TESTS. boxcox lgEARNSTAR AGE S SEX, model(rhsonly) nolog Number of obs = 570 LR chi2(4) = Log likelihood = Prob > chi2 = lgEARNSTAR | Coef. Std. Err. z P>|z| [95% Conf. Interval] /lambda | Test Restricted LR statistic P-Value H0: log likelihood chi2 Prob > chi lambda = lambda = lambda = Estimates of scale-variant parameters | Coef Notrans | _cons | Trans | AGE | S | SEX | /sigma |
 nolog Number of obs = 570 LR chi2(4) = 120.20 Log likelihood = -375.35439 Prob > chi2 = 0.000 ------------------------------------------------------------------------------ lgEARNSTAR | Coe")
177
ИНФОРМАЦИОННЫЕ КРИТЕРИИ

178
17 BOX-COX TESTS. reg EARNSTAR S Source | SS df MS Number of obs = F( 1, 568) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = EARNSTAR | Coef. Std. Err. t P>|t| [95% Conf. Interval] S | _cons | reg LGEARNSTAR S Source | SS df MS Number of obs = F( 1, 568) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = LGEARNSTAR | Coef. Std. Err. t P>|t| [95% Conf. Interval] S | _cons | icomp Information criteria AIC = SBIC = ICOMP = icomp Information criteria AIC = SBIC = ICOMP =
 = 65.64 Model | 30.818438 1 30.818438 Prob > F = 0.0000 Residual | 266.698183 568.469539054 R-squared = 0.1036 ------------")
179
ИНФОРМАЦИОННЫЕ КРИТЕРИИ. quietly reg EARNSTAR S. fitstat, saving(IC) Measures of Fit for regress of EARNSTAR Log-Lik Intercept Only: Log-Lik Full Model: D(568): LR(1): Prob > LR: R2: Adjusted R2: AIC: AIC*n: BIC: BIC': (Indices saved in matrix fs_IC). quietly reg lgEARNSTAR S. fitstat, force u(IC) Measures of Fit for regress of lgEARNSTAR Current Saved Difference Model: regress regress N: Log-Lik Intercept Only: Log-Lik Full Model: D: (568) (568) (0) LR: (1) (1) (0) Prob > LR: R2: Adjusted R2: AIC: AIC*n: BIC: BIC':
 Measures of Fit for regress of EARNSTAR Log-Lik Intercept Only: -623.498 Log-Lik Full Model: -592.332 D(568): 1184.664 LR(1): 62.331 Prob > LR: 0.000 R2: 0.104 Adjusted R2: 0.102 AI")
180
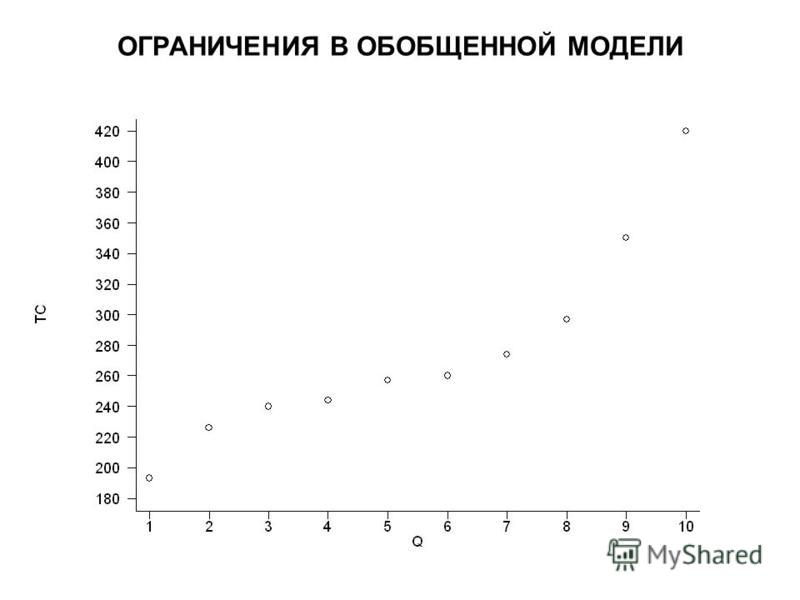
ОГРАНИЧЕНИЯ В ОБОБЩЕННОЙ МОДЕЛИ

190
. reg TC Q Source | SS df MS Number of obs = F( 1, 8) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = TC | Coef. Std. Err. t P>|t| [95% Conf. Interval] Q | _cons | ovtest Ramsey RESET test using powers of the fitted values of TC Ho: model has no omitted variables F(3, 5) = Prob > F =
 = 42.28 Model | 32780.3667 1 32780.3667 Prob > F = 0.0002 Residual | 6202.53333 8 775.316667 R-squared = 0.8409 -------------+----------------------")
191
ОГРАНИЧЕНИЯ В ОБОБЩЕННОЙ МОДЕЛИ

193
. reg TC Q3 Q2 Q Source | SS df MS Number of obs = F( 3, 6) = Model | Prob > F = Residual | R-squared = Adj R-squared = Total | Root MSE = TC | Coef. Std. Err. t P>|t| [95% Conf. Interval] Q3 | Q2 | Q | _cons | di _b[ Q2]^2-3*_b[Q]*_b[Q3] testnl _b[ Q2]^2=3*_b[Q]*_b[Q3] (1) _b[ Q2]^2 = 3*_b[Q]*_b[Q3] F(1, 6) = Prob > F = ovtest Ramsey RESET test using powers of the fitted values of TC Ho: model has no omitted variables F(3, 3) = 1.76 Prob > F =
 = 1202.22 Model | 38918.1562 3 12972.7187 Prob > F = 0.0000 Residual | 64.7438228 6 10.7906371 R-squared = 0.9983 -------------+--------------")
Еще похожие презентации в нашем архиве: